« Il y a des mensonges, des maudits mensonges et des statistiques » B.Disraeli
Pourquoi un tel dégoût pour un domaine qui, selon le Merriam-dictionnaire Webster, est simplement « une branche des mathématiques traitant de la collecte, de l’analyse, de l’interprétation et de la présentation de masses de données numériques. »1 Pourquoi le domaine de la statistique est-il sous un jour si négatif par tant de personnes ?
Il y a quatre raisons principales à cela
- C’est un domaine complexe. Même les concepts de base ne sont pas accessibles aisément et sont très difficile à expliquer
- Même les experts les mieux intentionnés peuvent mal appliquer les outils à leur disposition
- La troisième raison derrière toute cette haine est que ceux qui ont un agenda peuvent facilement créer des statistiques pour mentir lorsqu’ils communiquent avec nous
- La dernière raison est que les statistiques peuvent souvent sembler froides et distantes, rendant l’appropriation très complexes par le public
Les Déboires descriptifs
Les statistiques descriptives ont pour objectif de résumer les principales caractéristiques d’un ensemble de données. Cependant, un usage incorrect ou inapproprié peut conduire à des conclusions trompeuses. Un exemple typique est l’utilisation de la moyenne pour résumer une distribution, sans tenir compte de la variabilité ou de l’asymétrie. Une autre erreur courante est de présenter des pourcentages sans expliquer l’effectif total, ce qui peut induire en erreur sur l’ampleur réelle d’un phénomène. Il est donc crucial de comprendre les hypothèses et les limites de chaque mesure descriptive pour l’utiliser correctement.
Prenons l’exemple de l’analyse des salaires au sein d’une entreprise. Si l’on se contente de regarder la moyenne des salaires, on pourrait conclure que l’entreprise rémunère bien ses employés. Cependant, si les salaires de la direction sont très élevés comparativement au reste des employés, la moyenne serait biaisée à la hausse. Il serait plus pertinent d’utiliser la médiane qui donne le salaire du milieu, ou encore de regarder la distribution complète des salaires pour avoir une vue plus précise.
Les Incendies inférentiels
L’inférence statistique vise à tirer des conclusions sur une population à partir d’un échantillon de cette population. Cependant, ce processus est sujet à des erreurs. Les erreurs d’échantillonnage et les erreurs de type I et II sont courantes. De plus, les erreurs peuvent être exacerbées par la confusion entre corrélation et causalité. Il est essentiel d’avoir une solide compréhension des principes de l’inférence statistique pour éviter ces pièges.
Imaginons une étude de santé publique cherchant à établir un lien entre une habitude alimentaire particulière (comme manger bio) et un meilleur état de santé général. Si l’étude conclut à une corrélation positive, cela ne signifie pas forcément que manger bio cause un meilleur état de santé. Il pourrait y avoir des facteurs de confusion, comme le niveau de revenu ou le mode de vie, qui influencent à la fois l’habitude alimentaire et l’état de santé. Ici, on peut tomber dans le piège de confondre corrélation et causalité.
L'Échantillonnage glissant
L’échantillonnage est une étape cruciale dans tout processus de collecte de données. Pourtant, de nombreuses erreurs peuvent survenir à ce stade. L’échantillon peut ne pas être représentatif de la population cible, en raison de biais de sélection ou de non-réponse. De plus, la taille de l’échantillon peut être insuffisante pour détecter un effet. Il est donc essentiel de planifier soigneusement l’échantillonnage pour obtenir des résultats fiables.
Considérons une enquête de satisfaction client menée par une entreprise de commerce en ligne. Si l’entreprise ne sollicite que les avis des clients qui ont fait un achat récent, elle risque d’obtenir une image faussée de la satisfaction globale de sa clientèle. En effet, les clients insatisfaits peuvent avoir cessé de faire des achats et donc ne pas être inclus dans l’échantillon. C’est un exemple de biais de sélection.
L'insensibilité à la taille de l'échantillon
Une erreur courante dans l’analyse de données est d’ignorer l’impact de la taille de l’échantillon sur les résultats. Une taille d’échantillon importante peut rendre significatif un effet très faible, tandis qu’une taille d’échantillon trop petite peut ne pas avoir la puissance suffisante pour détecter un effet existant. De plus, la signification statistique ne signifie pas nécessairement une signification pratique. Ainsi, il est important de considérer la taille de l’échantillon dans l’interprétation des résultats.
Supposons que vous meniez une étude pour évaluer l’effet d’un médicament sur la baisse de la tension artérielle. Si vous avez un très grand échantillon de patients, vous pourriez constater une baisse statistiquement significative de la tension artérielle. Cependant, cette baisse peut être très faible, disons 0.1 mm Hg, une valeur cliniquement insignifiante malgré sa significativité statistique. C’est un exemple où la taille de l’échantillon peut rendre un effet faible significatif. D’un autre côté, si l’échantillon est trop petit, on peut passer à côté d’un effet réel. Il est donc important de considérer l’importance clinique ou pratique en plus de la significativité statistique.
En approfondissant cette question, Ben Jones (voir auteur ayant inspiré cet article) a réussi à trouver des chiffres sur le taux de cancer du rein ainsi que les données démographiques pour chaque comté américain, et il a créé un tableau de bord interactif (figure ci-dessous) pour illustrer visuellement le fait que Kahneman, Wainer et Zwerlink sont faire assez clairement dans les mots.
Remarquez quelques éléments dans le tableau de bord. Sur la carte choroplèthe (remplie), les comtés orange les plus foncés (taux élevés par rapport au taux global des États-Unis) et les comtés bleus les plus foncés (taux faibles par rapport au taux global des États-Unis) sont souvent côte à côte.
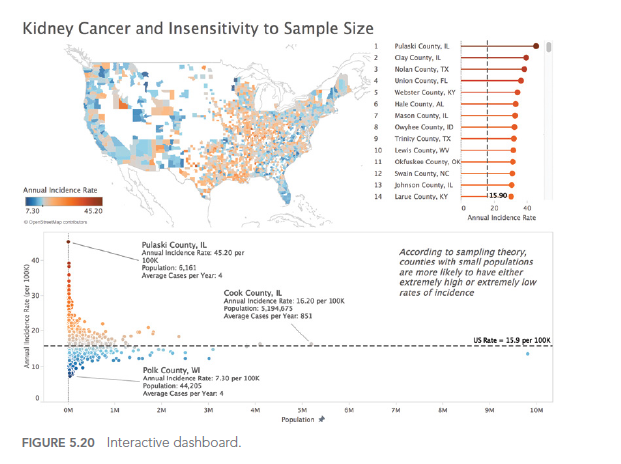
De plus, notez comment dans le nuage de points sous la carte, les marques forment une forme d’entonnoir, avec des comtés moins peuplés (à gauche) plus susceptibles de s’écarter de la ligne de référence (le taux global des États-Unis), et des comtés plus peuplés comme Chicago, L.A. , et New York sont plus susceptibles d’être proches de la ligne de référence globale.
Une dernière observation : si vous survolez un comté avec une petite population dans la version interactive en ligne, vous remarquerez que la moyenne
le nombre de cas par an est extrêmement faible, parfois 4 cas ou moins. Une petite déviation – même juste 1 ou 2 cas – dans une année suivante tirera un comté du bas de la liste vers le haut, ou vice versa.
Dans le prochain article, nous allons explorer le 5eme type d’erreur que nous pouvons rencontrer lorsque nous utilisons les données pour éclairer le monde qui nous entoure : Les aberrations analytiques.
Cet article est inspiré fortement par le livre « Avoiding Data pitfalls – How to steer clear of common blunders when working with Data and presenting Analysis and visualisation” écrit par Ben Jones, Founder and CEO de Data Litercy, edition WILEY. Nous vous recommandons cette excellente lecture!