La Data Engineering (ingénierie des données) c’est quoi ?
Encore un mot tendance ? On ne partage pas cet avis !
Bien que l’ingénierie des données ne soit pas un domaine nouveau, cette discipline semble être aujourd’hui sortie de l’ombre et propulsée au-devant de la scène.
Nous avions justement envie de parler « métier » comme on dit dans le jargon. Vous apprendrez donc dans cet article en quoi consiste le métier de « Data Engineer », et par conséquent ce que fait une partie de notre équipe au quotidien.

Un jour, un métier : ingénieur de données
La Data Engineering consiste au développement, à l’exploitation et à la maintenance d’une infrastructure de données, sur site ou dans le Cloud (ou hybride ou multicloud), comprenant des bases de données et des pipelines pour extraire, transformer et charger des données.
Une définition, please ?
La Data Engineering étroitement liée à la Data Science, fait partie de l’écosystème du Big Data. Bien que les data engineers (ingénieurs de données) ne reçoivent pas le même niveau d’attention que les data scientists, ils sont essentiels au processus de la science des données. Leur rôles et responsabilités varient en fonction du niveau de maturité des données et de l’organisation de l’entreprise.
Cependant, certaines tâches comme l’extraction, le chargement et la transformation des données, sont fondamentales et incontournables dans le métier du data engineer.
En général en ingénierie des données, on déplace des données d’un système vers un autre, ou on transforme des données dans un format vers un autre. En d’autres termes, le data engineer interroge les données d’une source (extract/extraire), effectue des traitements sur ces données (transform/transformer), et enfin place ces données d’un niveau de qualité de production, à un emplacement où les utilisateurs peuvent y accéder (load/charger). Les termes Extract, Transform et Load (ETL) correspondent aux étapes du processus présent dans les logiciels appartenant à la catégorie des ETL (comme Talend, très connu dans le milieu).
Toutefois, cette définition de l’ingénierie des données est large et simpliste.
A partir d’un exemple, voyons plus en détails en quoi consiste le métier, ça vous parlera sûrement un peu plus :
Un site web de e-commerce de détail vend des gadgets « high-tech » dans une grande variété de couleurs. Le site fonctionne avec une base de données relationnelle, et chaque transaction est stockée dans la base de données.

La problématique du moment : combien de gadgets bleus le détaillant a-t-il vendus au cours du dernier trimestre ?
Pour répondre à cette question, vous pouvez exécuter une requête SQL sur la base de données (SQL : Structured Query Language ; langage de requête structuré. Il s’agit c’est le langage qui est utilisé pour dialoguer et faire des traitements sur les bases de données relationnelles). Il est clair que pour une tâche simple comme celle-ci, vous n’avez pas besoin d’un data engineer mais à mesure que le site se développe, exécuter des requêtes sur la base de données de production n’est plus pratique. De plus, il peut y avoir plus d’une base de données qui enregistre les transactions, et ces bases peuvent se trouver à différents emplacements géographiques.
Par exemple, le site de e-commerce pourrait très bien avoir une base de données en Amérique du Nord, une autre en Asie, une autre en Afrique et enfin une autre en Europe.
Dans le domaine de l’ingénierie des données (la data engineering) ce genre de pratique est courante !
Pour répondre à la question précédente concernant les ventes de gadgets « high-tech » de couleurs bleus, le data engineer va créer des connexions à chacune des bases de données réparties dans les différentes régions, extraire les données, et les chargera dans un entrepôt de données. A partir de là, l’ingénieur peut maintenant effectuer une requête pour compter le nombre de gadgets bleus vendus.
Plutôt que de trouver le nombre de gadgets bleus vendus, les entreprises ont plus souvent tendance à chercher des réponses aux questions suivantes :
- Quelle région vend le plus de gadgets ?
- Quelles sont les heures où on observe un pic des ventes sur ce type de produit ?
- Combien d’utilisateurs mettent ce produit dans leur panier et le suppriment plus tard ?
- Quels sont les gadgets vendus ensemble ?
Vous avez des problématiques similaires ?
Pour répondre à ces questions, il ne suffit pas d’extraire les données et de les charger dans un système. Une transformation est requise entre l’extraction et le chargement. Il y a aussi la différence de fuseaux horaires dans les différentes régions. Par exemple, les Etats-Unis ont à eux seuls quatre fuseaux horaires. Pour cela, il faudra transformer les champs de date dans un format normalisé. Il faudra également trouver un moyen de distinguer les ventes dans chaque région. Cela pourrait se faire en ajoutant un champ « région » aux données. Ce champ doit-il être spatial, en coordonnées, ou sous forme de texte, ou s’agira-t-il simplement de texte qui pourrait être transformé dans un traitement d’ingénierie des données ?
Dans ce cas présent, le data engineer devra extraire les données de chaque base de données, puis transformer ces données en y ajoutant un champ supplémentaire pour la région. Pour comparer les fuseaux horaires, le data engineer doit être familiarisé avec les normes internationales de standardisation des données. Aujourd’hui, l’Organisation Internationale de Normalisation (ISO) a la norme – ISO 8601 pour faire face à cette problématique.
Donc pour répondre aux questions précédentes, l’ingénieur devra :
- Extraire les données de chaque base de données
- Ajouter un champ pour localiser la région de chaque transaction dans les données
- Transformer la date de l’heure locale dans la norme ISO 8601
- Charger les données dans l’entrepôt de données.
La suite d’étapes (extraction -> transformation -> chargement) est réalisée par la création de ce qu’on appelle un Pipeline (ou encore Job). Ce pipeline est une série de traitements successifs qui récupère en amont les données « brutes », pouvant contenir des fautes de frappe ou des données manquantes. Au fur et à mesure des traitements, les données sont nettoyées de sorte qu’à la fin du processus, ces dernières sont stockées dans un entrepôt de données et prêtes à être exploitées. Le schéma suivant illustre le pipeline requis pour accomplir les quatre tâches précédentes :
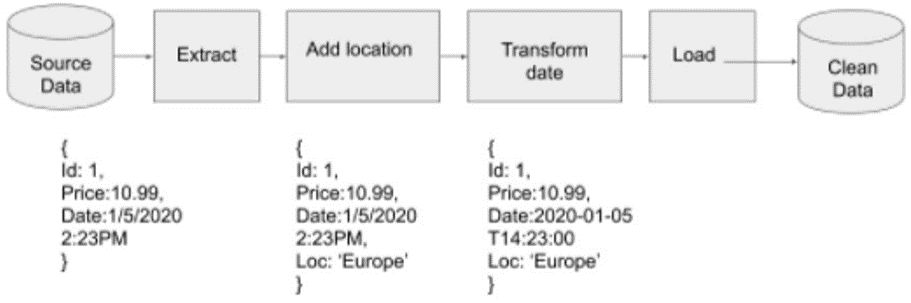
Figure 1: Pipeline qui ajoute une région et modifie la date
Après ce petit tour d’horizon sur ce qu’est l’ingénierie des données et ce que font les ingénieurs de données, vous devriez commencer à avoir une idée des responsabilités et des compétences que les ingénieurs de données doivent acquérir. Vrai ?
Quelles sont les connaissances et compétences requises pour être Data engineer ?
L’exemple précédent montre bien que le data engineer doit être familiarisé avec différentes technologies, et nous n’avons même pas encore mentionné les processus ou les besoins de l’entreprise.
Pour démarrer la première étape du processus d’un pipeline (l’extraction), le data engineer doit savoir comment extraire des données depuis des fichiers pouvant être en différents formats, ou depuis différents types de bases de données. L’ingénieur doit donc connaître plusieurs langages de programmation tels que SQL et Python, afin de pouvoir effectuer ces différentes tâches. Lors de la phase de transformation des données, il devra également maîtriser la modélisation et les structures de données. De plus, il doit aussi être en mesure de comprendre les besoins de l’entreprise et les informations ou connaissances qu’elle souhaite extraire des données, afin d’éviter les erreurs de conception du ou des modèles de données.
Le chargement des données dans l’entrepôt de données nécessite aussi que le data engineer connaisse les bases de conception d’un entrepôt de données, ainsi que les types de bases de données utilisés dans leur construction.
Enfin, l’ensemble de l’infrastructure sur laquelle le pipeline de données s’exécute peut également être sous la responsabilité de l’ingénieur de données. Il doit savoir comment administrer des serveurs Linux, et comment installer et configurer des logiciels tels qu’Apache Airflow ou NiFi.
Les entreprises ont de plus en plus tendance aujourd’hui à migrer vers le cloud, et incitent donc les Data engineer à se familiariser avec la mise en place de l’infrastructure sur des plateformes cloud comme Amazon, Google Cloud Platform ou Azure.
Nous sommes heureux de vous avoir partagé le métier data engineers et on espère que vous y voyez plus clair désormais !