Commençons par définir ce qu’est l’épistémologie.
L’épistémologie (du grec ancien ἐπιστήμη / epistémê « connaissance vraie, science » et λόγος / lógos « discours ») est un domaine de la philosophie qui peut désigner deux champs d’étude : l’étude critique des sciences et de la connaissance scientifique (ou de l’œuvre scientifique).
Autrement dit, il s’agit de la manière dont nous construisons nos connaissances.
Dans le monde de la donnée, il s’agit d’un sujet central et critique. En effet, nous avons été familiarisés avec le processus de transformation de la donnée, en informations, en connaissance et en élément de sagesse :
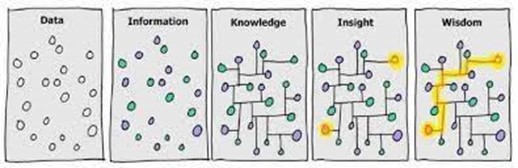
Ici le problème trouve sa source dans la manière dont nous considérons notre point de départ : les données ! En effet, l’utilisation de celle-ci et sa transformation au cours des étapes suivantes relèvent de procédés et processus conscients et maîtrisés :
==>Je nettoie ma donnée, la traite dans un ETL / ELT, la stocke, la visualise, communique mon résultat et le partage etc. Cette maîtrise nous donne le contrôle sur la qualité des étapes. Toutefois, on aura tendance à se lancer dans ce travail de transformation de notre ressource primaire en omettant un point crucial, source de notre premier obstacle :
LA DONNEE N’EST PAS UNE REPRESENTATION EXACTE DU MONDE REEL !
En effet, il est excessivement simple de travailler avec des données en pensant aux données comme étant la réalité elle-même et pas comme des données collectées à propos de la réalité. Cette nuance est primordiale :
- Ce n’est pas la criminalité, mais les crimes déclarés
- Ce n’est pas le diamètre d’une pièce mécanique mais le diamètre mesuré de cette pièce
- Ce n’est pas le sentiment du public par rapport à un sujet mais le sentiment déclaré des personnes qui ont répondu à un sondage
Entrons dans le détail de cet obstacle avec quelques exemples :
1. Ce que nous ne mesurons pas (ou ce que nous ne mesurions pas)
Regardons ensemble ce dashboard présentant l’ensemble des impacts de météorites sur la Terre entre -2500 et 2012. Pouvez vous identifiez ce qu’il y a d’étranges ici ?
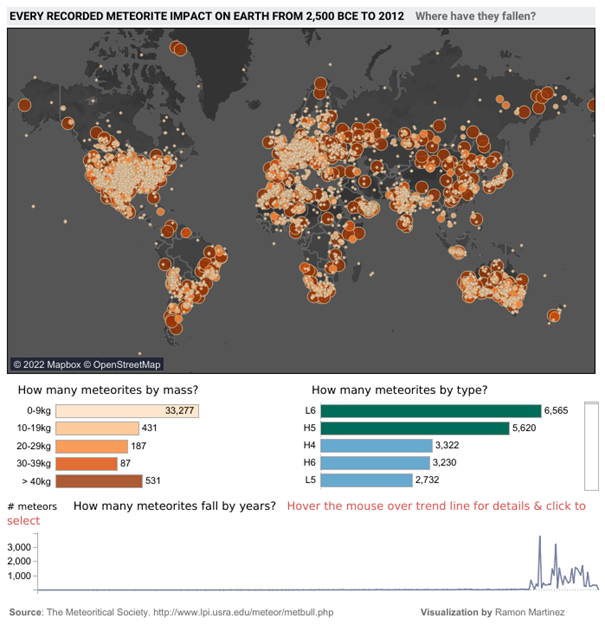
Les météorites semblent avoir évité soigneusement certaines parties de la planète, une large part de l’Amérique du Sud, de l’Afrique, de la Russie, du Groenland etc. Et si l’on se concentre sur le graphique montrant le nombre de météorites par années, que celles-ci ont eu tendance à tomber plutôt dans les 50 dernières années (et presque pas sur l’ensemble de la période couvrant -2055 à 1975).
Est-ce qu’il s’agit bien de la réalité ? Ou plutôt de défauts dans la manière dont les données ont été collectées
- Nous avons commencé à collecter systématiquement ces informations récemment et nous basons sur l’archéologie pour essayer de déterminer les impacts du passé. L’érosion et le temps faisant leurs œuvres, les traces de la grande majorité des impacts ont ainsi disparu et ceux-ci ne peuvent donc plus être comptabilisés (et non, les météorites n’ont pas commencé à pleuvoir en 1975).
- Pour qu’un impact de météorite soit intégré dans une base de données, il faut que celui-ci soit enregistré. Et pour cela, il faut une observation, et donc un observateur et que celui-ci sache à qui remonter cette information. Deux biais impactant largement la collecte et permettant d’expliquer les larges zones de Terre qui semblent avoir été épargnées par la chute de météorite.
2. Le système de mesure ne fonctionne pas
Parfois, la cause de cet écart entre la donnée et la réalité peut être expliqué par un défaut du matériel de collecte. Malheureusement, tout ce qui est fabriqué par un être humain en ce bas monde est susceptible d’être défaillant. Cela vaut pour les capteurs et les instruments de mesure évidemment.
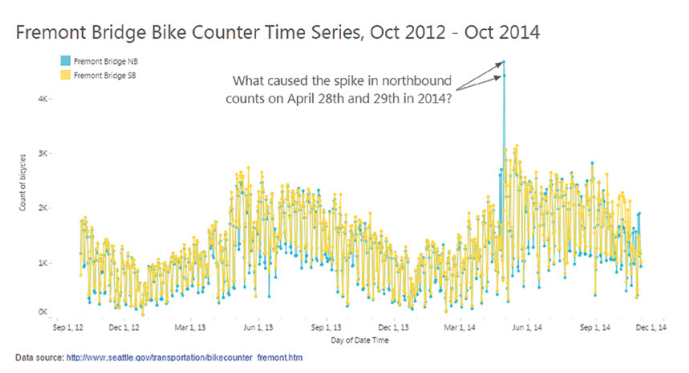
Que s’est-il passé les 28 et 29 avril 2014 sur ce pont ? Il semblerait qu’il y ait un énorme pic de traversée du pont de Fremont par des vélos mais uniquement dans un seul sens (courbe bleue).
Source : 7 datapitfalls – Ben Jones
Série temporelle du nombre de vélos traversant le pont de Fremont
On pourrait penser qu’il s’agissait d’une magnifique journée d’été et que tout le monde est passé sur le pont en même temps ? D’une course de vélos n’empruntant celui-ci que dans un sens ? Que tous les pneus de toutes les personnes ayant traversé le pont à l’aller ont crevé avant le retour ?
Plus prosaïquement, il s’avère que le compteur bleu avait un défaut ces jours précis et ne comptait plus correctement les traversées du pont. Un simple changement de batterie et du capteur et le problème a été résolu.
Maintenant, posez vous la question du nombre de fois où vous avez pu être induit en erreur par des données issues d’un capteur ou d’une mesure défaillante sans que cela n’ait été perçu ?
3. Les données sont trop humaines
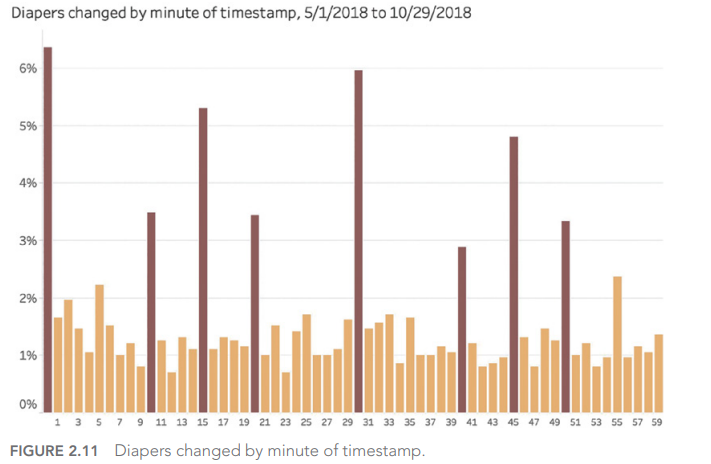
Et oui, nos propres biais humains ont un effet important sur les valeurs que nous enregistrons lors de la collecte d’informations. Nous avons par exemple tendance à arrondir les résultats des mesures :
Source : 7 datapitfalls – Ben Jones
Si l’on s’en fit à ses données, le changement des couches se fait plus régulièrement toutes les 10 minutes (0, 10, 20, 30, 40, 50) et parfois sur certains quarts d’heure (15, 45). Cela serait assez incroyable n’est-ce pas ?
Il s’agit bien d’un récit incroyable. En effet, il faut se pencher ici sur la manière dont les données ont été collectées. En tant qu’être humain, nous avons cette tendance à arrondir les informations lorsque nous les enregistrons, notamment lorsque nous regardons une montre ou une horloge : pourquoi ne pas indiquer 1:05 lorsqu’il est 1 :04 ? ou encore plus simple 1:00 car c’est plus simple encore ?
On retrouvera ce type de simplification humaine dans toutes les collectes de mesures : poids, tailles, etc.
4. Le Cygne Noir !
Dernier exemple que nous souhaitons mettre en avant ici, et ce que l’on appelle l’effet « Cygne Noir ». Si nous pensons que les données dont nous disposons sont une représentation exacte du monde qui nous entoure et que nous pouvons en sortir des affirmations à graver dans le marbre ; alors nous nous trompons fondamentalement sur ce qu’est une donnée (cf. précédemment).
Le meilleur usage des données est d’apprendre ce qui n’est pas vrai à partir d’une idée préconçue et de nous guider dans les questions que nous devons nous poser pour en apprendre plus ?
Mais revenons à notre cygne noir :
Avant la découverte de l’Australie, toutes les observations de cygne jamais faite pouvaient conforter les européens que tous les cygnes étaient blancs, à tort ! En 1697, l’observation d’un cygne noir a remis intégralement en question cette préconception commune.
Et le lien avec les données ? De la même manière que l’on aura tendance à croire qu’une observation répétée est une vérité générale ; à tort ; on peut être amener à inférer que ce que nous voyons dans les données que nous manipulons peut s’appliquer de manière générale au monde qui nous entoure et à toute époque. C’est une erreur fondamentale dans l’appréciation des données.

5. Comment se prémunir de l’erreur épistémologique ?
Il suffit pour cela d’une légère gymnastique mentale et d’un peu de curiosité :
- Comprendre clairement comment ont été définies les mesures
- Comprendre et représenter le processus de collection des données
- Identifier les limites et erreurs de mesure possibles dans les données utilisées
- Identifier les changements dans la méthode et les outils de mesure dans le temps
- Comprendre les motivations des personnes ayant collecté les données
Dans le prochain article, nous allons explorer le 2ème type d’obstacle que nous pouvons rencontrer lorsque nous utilisons les données pour éclairer le monde qui nous entoure : Les Erreurs Techniques
Cet article est inspiré fortement par le livre « Avoiding Data pitfalls – How to steer clear of common blunders when working with Data and presenting Analysis and visualisation” écrit par Ben Jones, Founder and CEO de Data Litercy, edition WILEY. Nous vous recommandons cette excellente lecture!
Pour retrouver l’intégralité des sujets qui seront abordés au cours de cette série par ici : https://www.datanalysis.re/blog/business-intelligence/data-les-7-pieges-a-eviter-ep-1-7/