Nous avons tous un jour exprimé notre incrédulité quant à l’intérêt des mathématiques dans notre vie quotidienne. A quoi ce sujet dense et complexe pouvait bien servir ? Et bien, dans un monde où les données sont présentes partout et infusent chaque décision stratégique des organisations, les mathématiques sont d’une importance vitale (nda : elles l’ont toujours été !)
Dans nos projets d’analyse de données, les erreurs mathématiques peuvent arriver dès lors qu’un champ calculé est créé pour générer des informations supplémentaires à partir de notre jeu de données initial. Ce type d’erreur peut être retrouvé par exemple lorsque :
- On réalise des agrégations (somme, moyenne, médiane, minimum, maximum, comptage, comptage distinct etc.) à différents niveaux de détail
- Nous faisons des divisions pour produire des ratios ou des pourcentages
- Nous travaillons avec des unités différentes
Il s’agit évidemment d’une infime partie des types d’opérations où des erreurs peuvent se glisser. Mais au regard de notre expérience, ce sont les causes principales de problème que nous rencontrons.
Et, dans chacun de ces cas, il ne faut pas être un ingénieur ou scientifique de génie pour les corriger. Un peu d’attention et pas mal de rigueur sont nécessaires !
1. Les erreurs de traitement d’unité
Dans cet article, nous n’allons pas trop nous attarder sur cette erreur fréquente. En effet, il existe un nombre important d’articles et d’anecdotes qui illustrent parfaitement et en détail ce type de problématique (dont nous avons également parlé dans l’article précédent).
L’exemple le plus fameux, et coûteux, est le crash de la sonde « Mars Orbiter ». Si vous voulez en savoir plus alors cela sera par ici : Mars Climate Orbiter – Wikipedia
Vous pouvez arguer qu’aucun d’entre nous ne fait partie de la NASA et doit poser une sonde sur une planète lointaine et donc ne pas être concerné. Et bien, vous pouvez à votre mesure, vous retrouver nez à nez avec ce type d’erreur lorsque vous manipulez des données temporelles (heures, jours, secondes, minutes, années), financières (différentes devises), ou que vous gériez des stocks (unités, kilos, palettes, barres etc.).

2. Aggravation des agrégations
Nous agrégeons des données lorsque nous regroupons des enregistrements qui ont un attribut en commun. Il y a toutes sortes de regroupements de ce genre que nous traitons dans notre monde dès lors que nous pouvons établir des liens hiérarchiques ; le temps (jour, semaine, mois, années), la géographie (villes, région, pays), les organisations (employés, équipes, sociétés) etc.
Les agrégations sont un outil puissant pour appréhender le monde, mais attention, elles comportent plusieurs facteurs de risque :
- Les agrégations résument une situation et ne présentent pas les informations détaillées. Tous ceux qui ont participé à une formation sur la datavisualisation avec nos équipes sont familiers du quarter d’Anscombe :
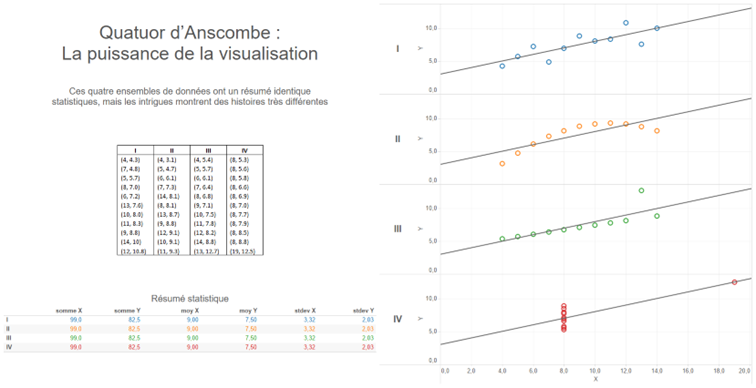
Le résumé statistique est un exemple typique de ce que peuvent masquer des agrégats. Dans cet exemple les quatre jeux de données ont exactement les mêmes sommes, moyennes et déviation standards sur les deux coordonnées (X,Y). Lorsque l’on représente chacun des points sur des courbes, il est aisé de constater que les 4 histoires sont significativement différentes.
Dès lors que des données sont agrégées, nous essayons de résumer une situation. Il faut toujours se rappeler que ce résumé masque les détails et le contexte qui l’expliquent. Alors soyez prudent lorsque, lors d’une discussion, vos interlocuteurs ne parlent que de valeurs moyenne, de sommes ou de médiane sans entrer dans le détail de ce qui a pu engendrer ce scénario précis.
- Les agrégations peuvent également masquer les valeurs manquantes et induire en erreur. En effet, selon la façon dont nous représentons des informations, il est possible que le fait que des données soient manquantes ne soit pas clairement visibles de prime abord.
Prenons par exemple un jeu de données dans lequel nous observons pour une compagnie aérienne le nombre d’impacts d’oiseaux sur des avions.
Notre objectif est de déterminer le (ou les) mois de l’année où le plus d’incidents ont été relevés. Cela donne :
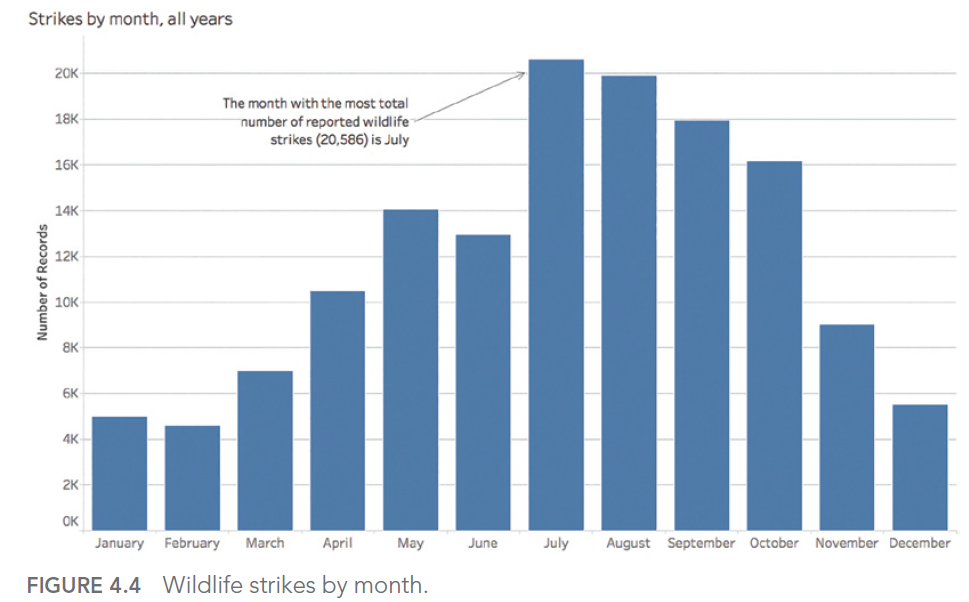
Le mois de juillet semble être le mois où le nombre d’impacts décomptés a été le plus important. Toutefois, si nous regardons le détail par année, nous nous rendons compte que l’agrégation choisie pour répondre à notre interrogation ne permettait pas de déterminer que les saisies pour l’année 2017 s’arrêtaient lors de ce fameux mois de juillet :
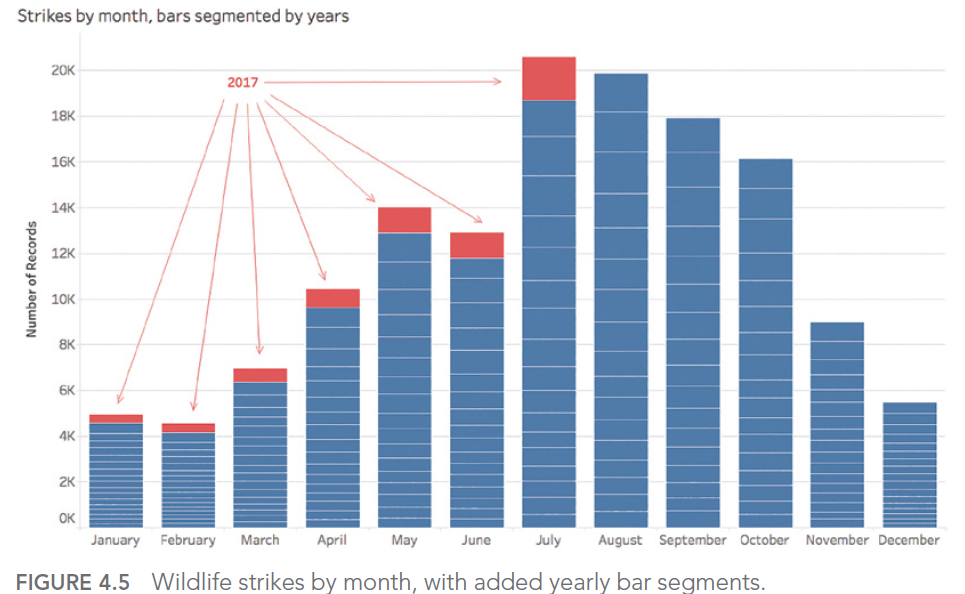
La réponse à notre question était donc le mois d’Août si nous excluons les données de l’année pour laquelle nous n’avions pas tous les enregistrements.
- Totaux et agrégations :
Dernier exemple de problématiques liées aux agrégations que nous allons découvrir dans cet article. Il s’agit d’une des erreurs « favorites » de l’auteur de cet article. D’aucun pourrait même parler de spécialité !
Elle intervient lorsqu’il est nécessaire de compter les individus distincts dans une population donnée. Mettons que nous regardons notre base client et cherchons à savoir combien d’individus uniques sont présents dans celle-ci.
Le comptage des id distincts pour l’ensemble de la société nous donne un décompte de nos clients uniques :

Mais si l’on regarde par ligne de produit et affichons une somme sans y prêter attention :

Nous trouvons 7 clients de plus !
Cela arrive simplement car il existe dans la clientèle de la société étudiée des clients qui prennent à la fois des prestations ET des licences, et qui finissent par être comptés deux fois dans le total !
Il s’agit d’un problème ayant des solutions simples dans tous les logiciels modernes de datavisualisation et de BI mais celui-ci à tendance à se cacher au détour d’une série de calculs et d’agrégations, causant des écarts parfois surprenants en bout de chaîne.
3. Panique à bord, un ratio !
Nous allons illustrer ce point avec un exemple sorti de l’un des dashboards que nous avons fait pour un de nos clients. Avec toute notre expertise, il nous arrive aussi de sauter à pieds joints dans ce type d’erreurs :

Et oui, il s’agit d’un taux d’occupation qui excède « légèrement » les 100% !
Comment est-ce possible ? Un simple oubli !
La somme des divisions n’est pas égale à la division des sommes…
En effet, dans ce cas précis, nous avions un jeu de données similaire à celui ci-dessous :
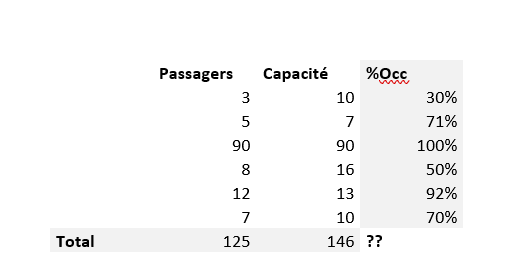
Est-ce que le taux d’occupation est égal à :
- La somme des taux d’occupation individuels ? FAUX !
Cela nous donne un total de 30 % + 71 % + 100 % + 50 % + 92 % +70 % soit 414 %.
Et c’est exactement l’erreur que nous avons faite sur un jeu de données encore plus vaste…
- Ou le ratio du total des passagers sur le total de la capacité disponible ? 125/146 = 86%. C’est plus juste !
Remarque : la moyenne des taux d’occupation individuels serait également fausse.
En résumé, dès lors que l’on manipule un ratio, il s’agit de diviser le total des valeurs du numérateur et du dénominateur pour éviter ce type de soucis.
Il s’agit dans ce cas précis d’un seul exemple d’erreur liée au ratio. Des mentions honorables peuvent être attribuées au traitement des valeurs NULL dans un calcul, ou à la comparaison de ratios qui ne sont pas calculés avec les mêmes dénominateurs.
Dans le prochain article, nous allons explorer le 4ème type d’obstacle que nous pouvons rencontrer lorsque nous utilisons les données pour éclairer le monde qui nous entoure :
Les dérapages statistiques. (Spoilers : « There are lies, damned lies and statistics » B.Disraeli)
Cet article est inspiré fortement par le livre ” Avoiding Data pitfalls – How to steer clear of common blunders when working with Data and presenting Analysis and visualisation” écrit par Ben Jones, Founder and CEO de Data Litercy, édition WILEY. Nous vous recommandons cette excellente lecture!
Pour retrouver l’intégralité des sujets qui seront abordés au cours de cette série par ici : https://www.datanalysis.re/blog/business-intelligence/data-les-7-pieges-a-eviter-intro/