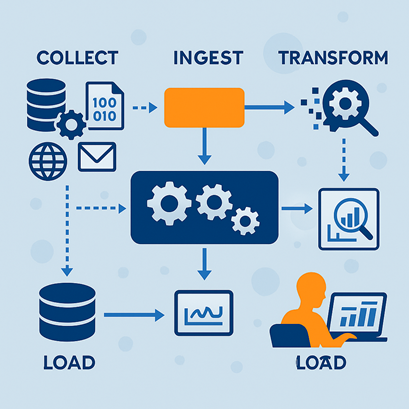
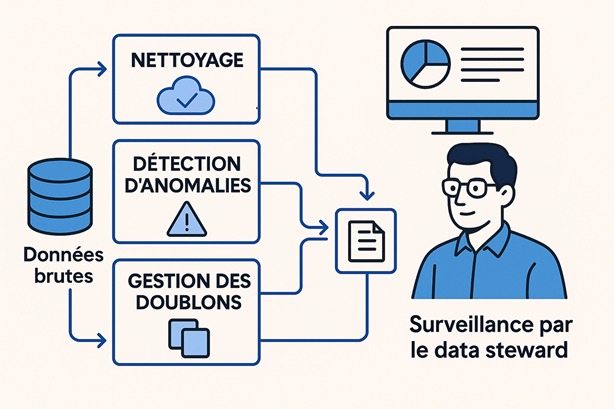
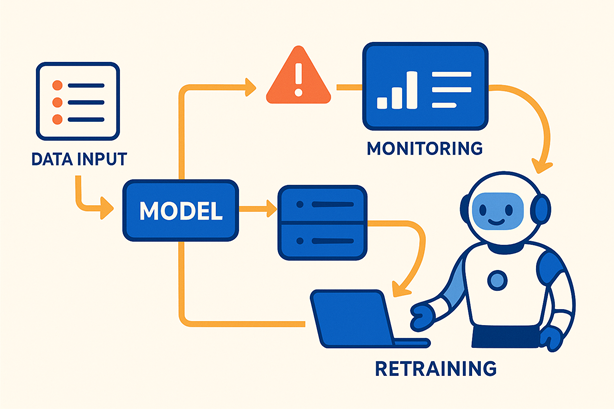
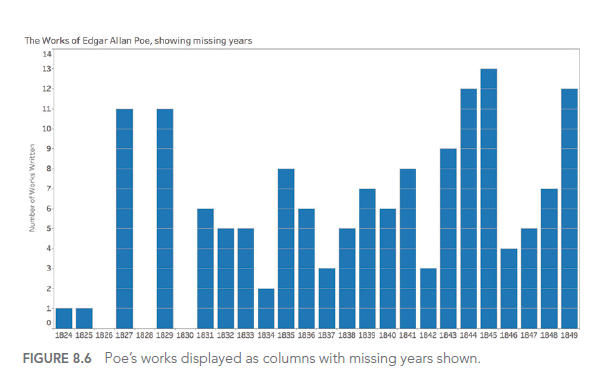
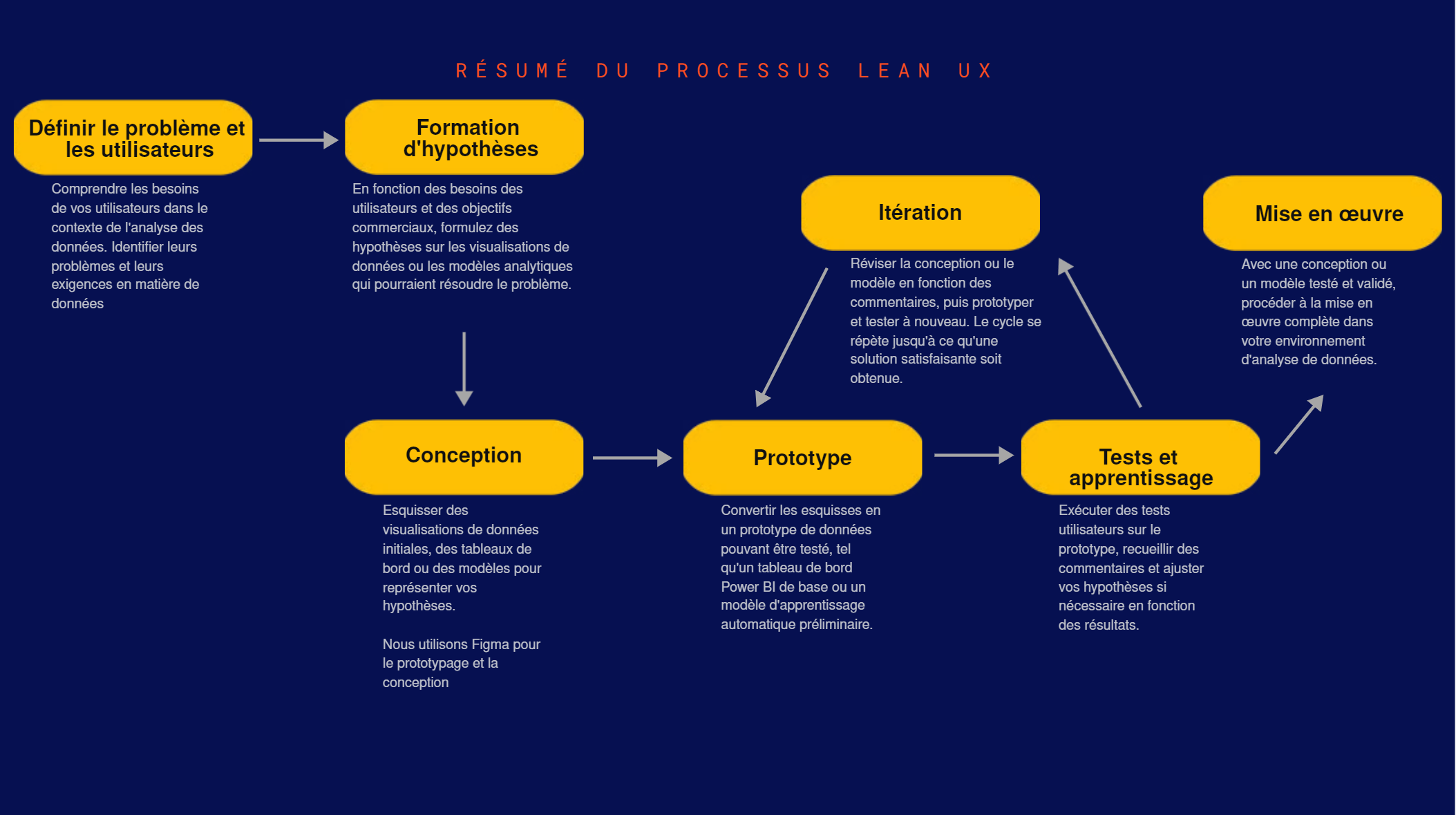
Qu’est-ce qu’une « Full-Stack AI Company » et pourquoi votre entreprise devrait s’y intéresser?
La révolution qui redéfinit le conseil data
L’intelligence artificielle ne se contente plus d’être un simple outil – elle redéfinit complètement la manière dont les entreprises abordent leurs défis data. Chez DATANALYSIS, nous sommes au cœur de cette métamorphose, transformant notre approche du conseil pour vous offrir des solutions plus puissantes et plus intégrées que jamais.
Définition d’une « Full-Stack AI Company »
Une « full-stack AI company » applique directement les capacités d’IA pour fournir des solutions complètes dans un domaine spécifique, plutôt que de simplement vendre des outils pour que d’autres les implémentent. Cette approche révolutionne le modèle d’affaires traditionnel du conseil.
Comme l’explique Y Combinator en 2025 : « Une entreprise full-stack IA ne se contente pas de construire des agents IA à vendre aux entreprises existantes ; elle crée de nouvelles entreprises dotées d’agents IA qui concurrencent directement les sociétés traditionnelles. »
| Full-Stack AI Companies | Entreprises d’outils IA traditionnelles |
|---|---|
| Construisent des solutions complètes qui répondent directement aux défis sectoriels | Créent des outils que d’autres intègrent dans leurs workflows |
| Possèdent l’expérience utilisateur et la relation client | Fournissent des composants qui s’intègrent aux systèmes des autres |
| Capturent l’ensemble de la chaîne de valeur d’un secteur | Capturent uniquement la couche technologique |
Pourquoi est-ce révolutionnaire pour votre entreprise ?
1. Transformation du temps en valeur
Pour un DSI comme vous, le temps est précieux. Notre approche full-stack IA permet de réduire drastiquement les délais de mise en œuvre :
- 40-50% de réduction du temps de développement ETL
- Diminution significative du temps d’actualisation des données (de 500 à 45 minutes chez un de nos clients)
- 70% de réduction du temps de programmation
2. De la donnée à la décision en un temps record
Comme en témoigne KDI, notre client : « Tous les objectifs majeurs liés à la gestion et à l’exploitation des données ont été atteints. La prestation de DATANALYSIS a été une ressource inestimable pour notre service, offrant une aide précieuse à la prise de décision. »
3. Expertise humaine amplifiée, non remplacée
Notre approche full-stack IA ne remplace pas l’expertise humaine – elle l’amplifie. Nos consultants se concentrent désormais sur des tâches à plus haute valeur ajoutée :
- Orientation stratégique
- Gouvernance des données
- Conseil en implémentation IA
- Éthique et conformité
En pratique : DUKE Analytics, notre assistant IA au cœur de notre transformation
DUKE Analytics, notre solution phare, incarne parfaitement cette approche full-stack IA :
« Dans l’univers complexe des données, DUKE Analytics émerge comme un phare de simplicité et de puissance, redéfinissant la manière dont les entreprises interagissent avec leurs informations cruciales. Grâce à sa technologie de BI Générative et à son datamanagement intelligent, DUKE Analytics démocratise l’usage des données. »
Cette solution permet de :
- Interagir : Dialoguer naturellement avec vos données via une interface chatbot
- Décider : Transformer les données en insights actionnables
- Briller : Prendre des décisions rapides et fondées
Témoignages clients : des résultats concrets
Notre approche full-stack IA a déjà transformé les opérations de plusieurs entreprises :
- Orange Réunion Mayotte : « DATANALYSIS nous accompagne depuis 6 ans au quotidien et c’est naturellement vers eux que nous nous sommes tournés pour notre projet stratégique de refonte de notre infrastructure et de nos outils data. »
- C-Care (secteur santé) : « L’équipe de DATANALYSIS a su faire la différence sur l’aspect opérationnel en fournissant à CCARE des pipelines plus rationalisés et une diminution significative du temps nécessaire à l’actualisation quotidienne des données en passant de 500 minutes à 45 minutes ! »
Prêt à transformer votre approche data ?
La révolution full-stack IA n’en est qu’à ses débuts. Les entreprises qui l’adoptent aujourd’hui se positionnent comme les leaders de demain.
Chez DATANALYSIS, nous combinons l’expertise humaine et les capacités IA pour offrir des solutions complètes qui s’attaquent directement à vos défis sectoriels, créant une valeur nettement supérieure aux approches traditionnelles.
Contactez-nous pour découvrir comment notre approche full-stack IA peut transformer votre entreprise.
DATANALYSIS – Transformez vos intuitions en décisions éclairées grâce à des données de qualité.