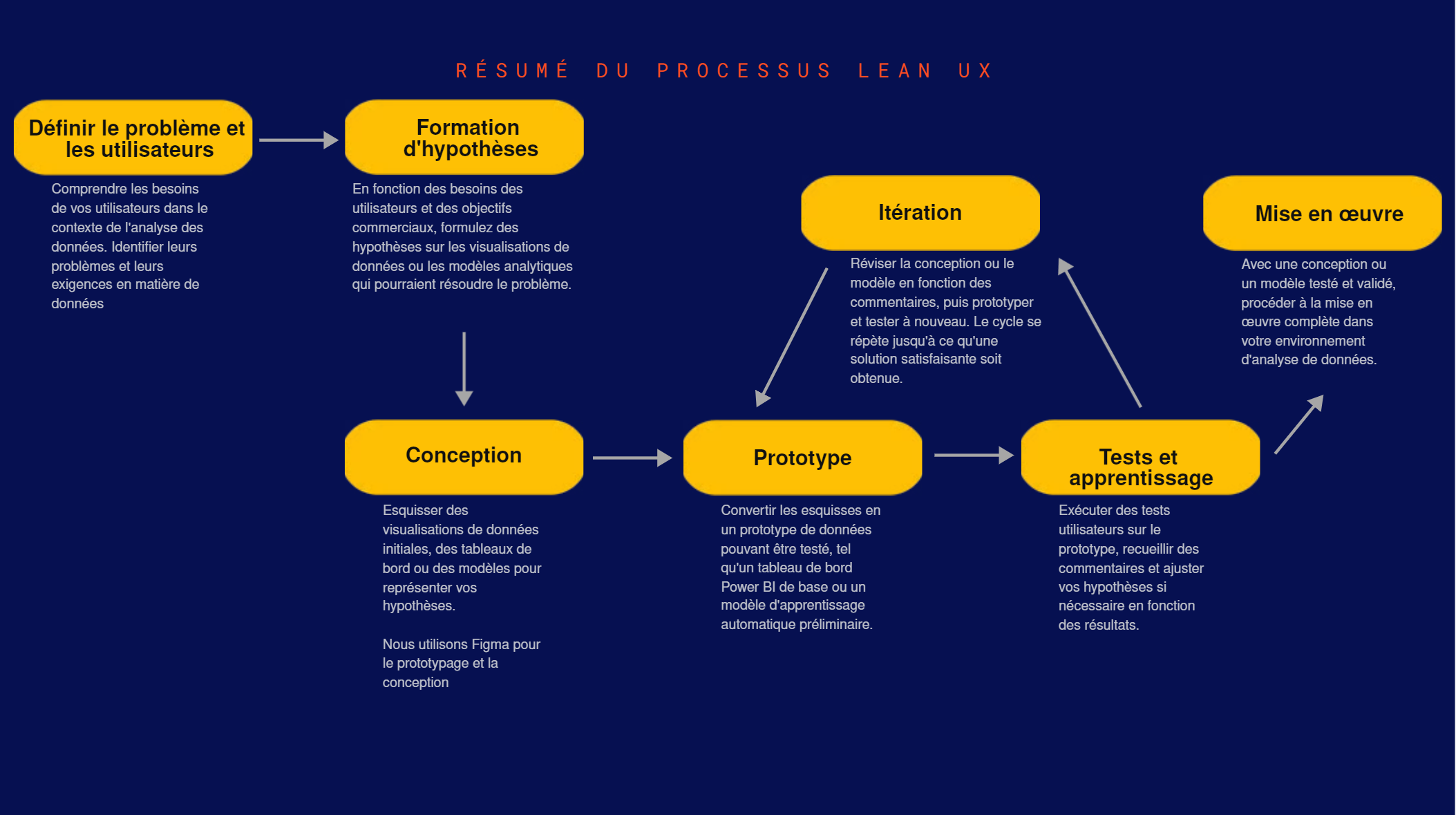
DATA: Les 7 pièges à éviter, Ep 7/7 – Dangers du design
L’importance du design dans la présentation des données
Le design joue un rôle crucial dans la façon dont les données sont perçues et interprétées. Un bon design peut rendre les données plus accessibles et compréhensibles, tandis qu’un mauvais design peut conduire à des malentendus et des interprétations erronées. Dans ce dernier épisode de notre série, nous explorerons les dangers liés au design dans la présentation des données.
Piège 7A: les couleurs confuses
Le choix des couleurs est un aspect crucial du design de visualisation de données. Des couleurs mal choisies peuvent rendre la visualisation difficile à lire ou induire en erreur. Voici quelques pièges courants :
- Utiliser trop de couleurs : Cela peut surcharger visuellement et rendre la compréhension difficile.
- Choisir des couleurs qui ne se distinguent pas bien : Cela peut rendre difficile la différenciation des catégories.
- Ignorer le daltonisme : Certaines combinaisons de couleurs peuvent être indiscernables pour les personnes daltoniennes.
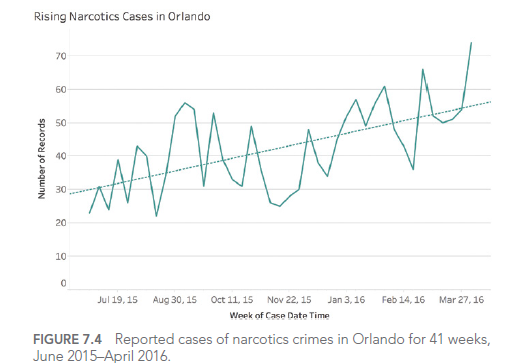
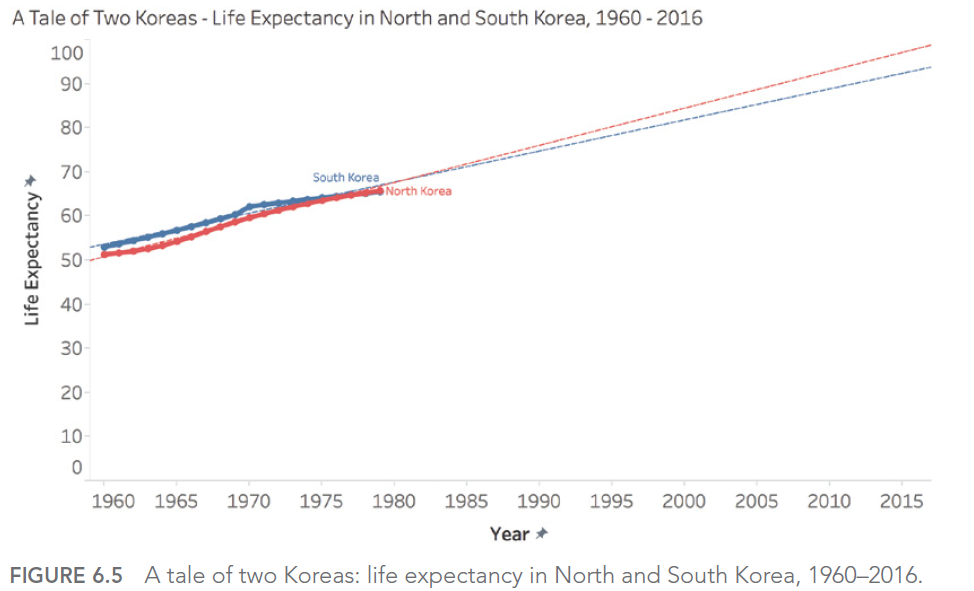
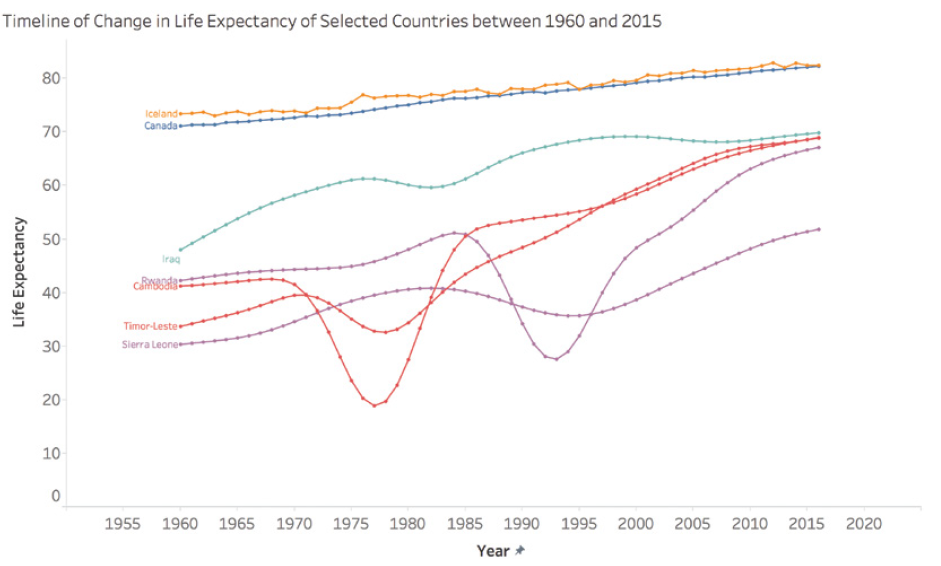
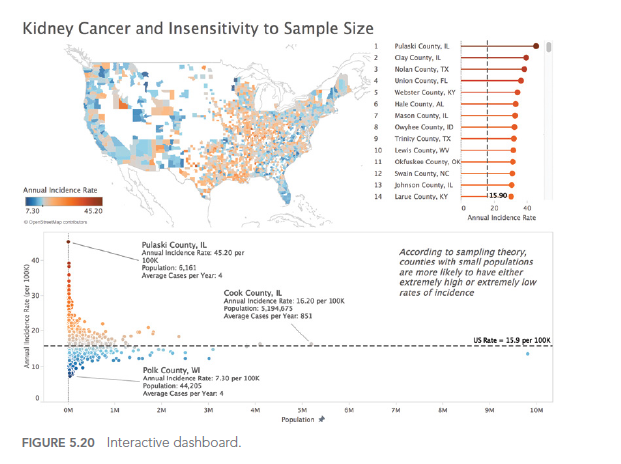
Considérons cet exemple de dashboard sur les crimes à Orlando :
Dans ce dashboard, l’utilisation de couleurs similaires pour différentes catégories rend difficile la distinction entre les types de crimes.
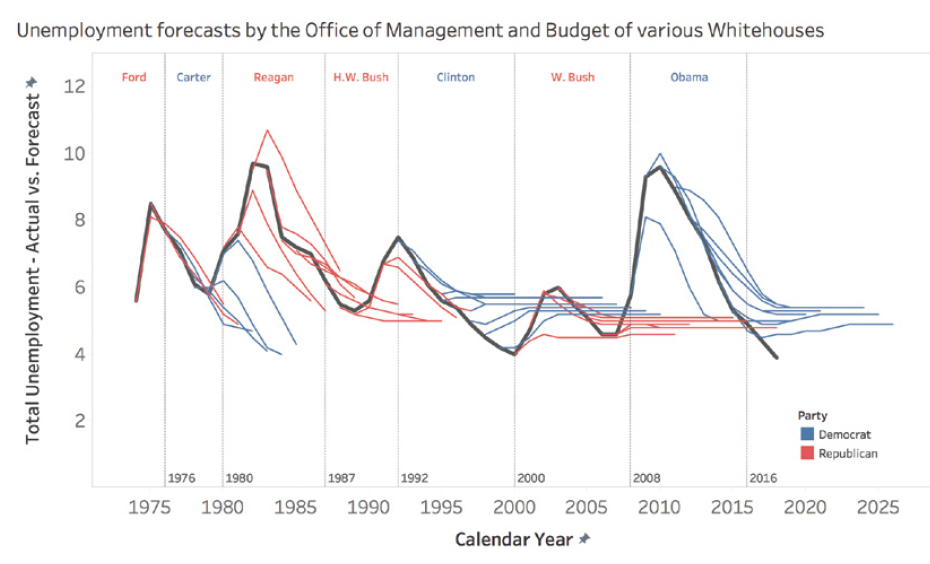
Piège 7B: les opportunités manquées
Parfois, dans notre quête de simplicité, nous pouvons manquer des opportunités d’améliorer la compréhension à travers le design. Par exemple, l’ajout judicieux d’éléments visuels peut grandement améliorer l’engagement et la mémorisation.
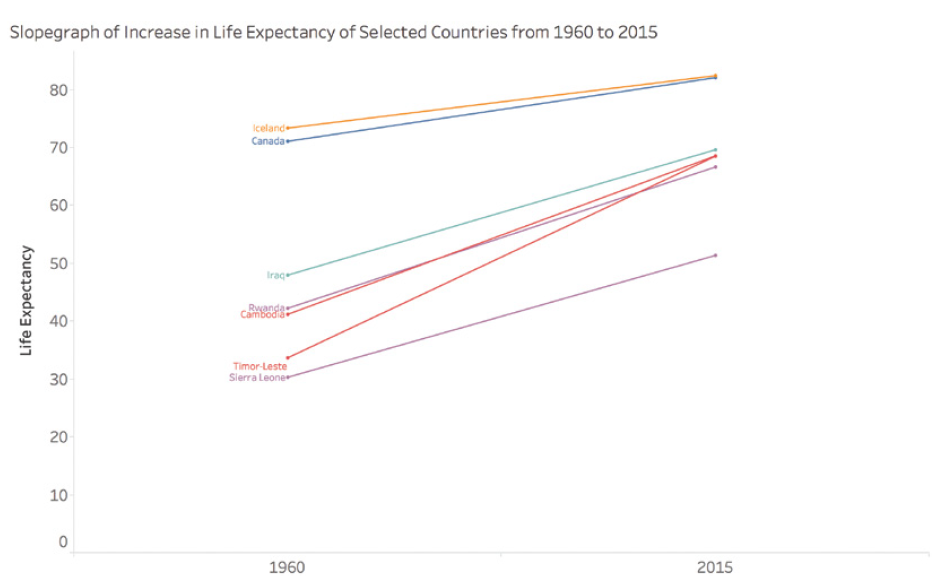
Voici un exemple d’une visualisation améliorée des œuvres d’Edgar Allan Poe :
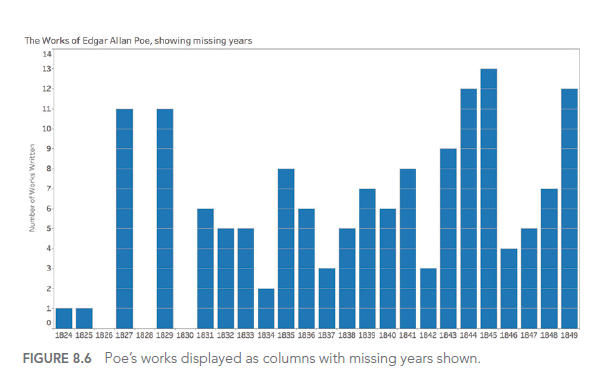
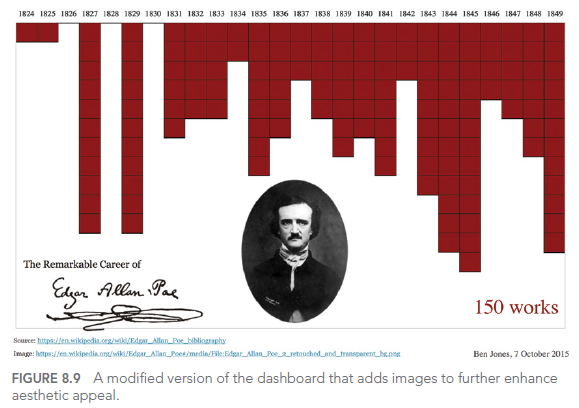
Cette visualisation utilise des éléments de design pour évoquer l’ambiance sombre des œuvres de Poe, rendant la visualisation plus mémorable et engageante.
Piège 7C: les problèmes d'utilisabilité
Un bon design ne se limite pas à l’aspect visuel, il doit également prendre en compte l’utilisabilité. Des visualisations difficiles à manipuler ou à comprendre peuvent frustrer les utilisateurs et limiter l’efficacité de la communication des données.
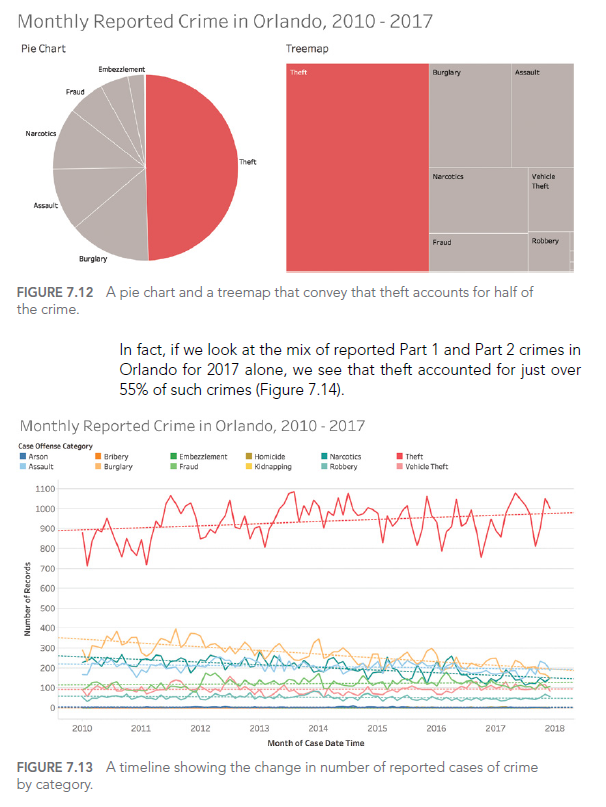
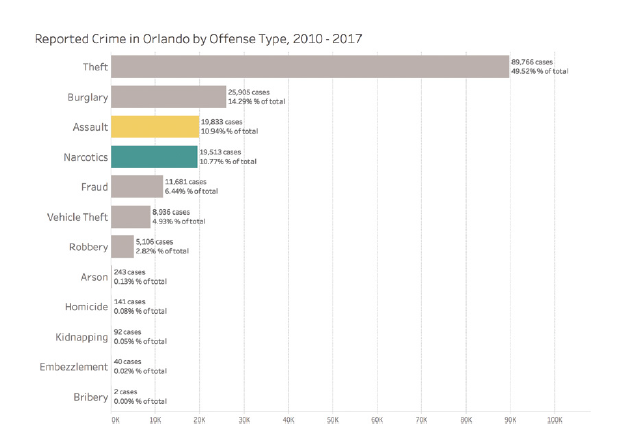
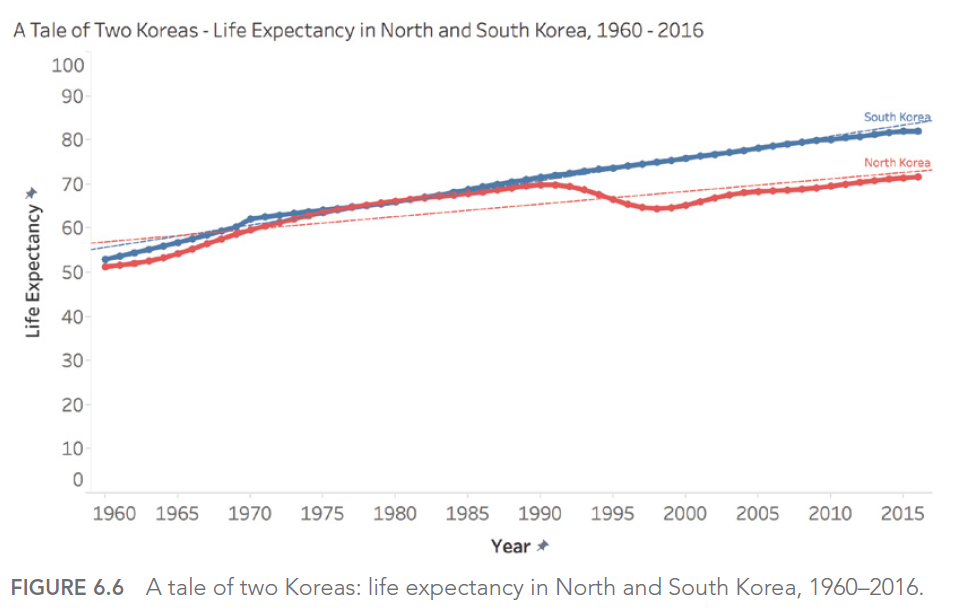
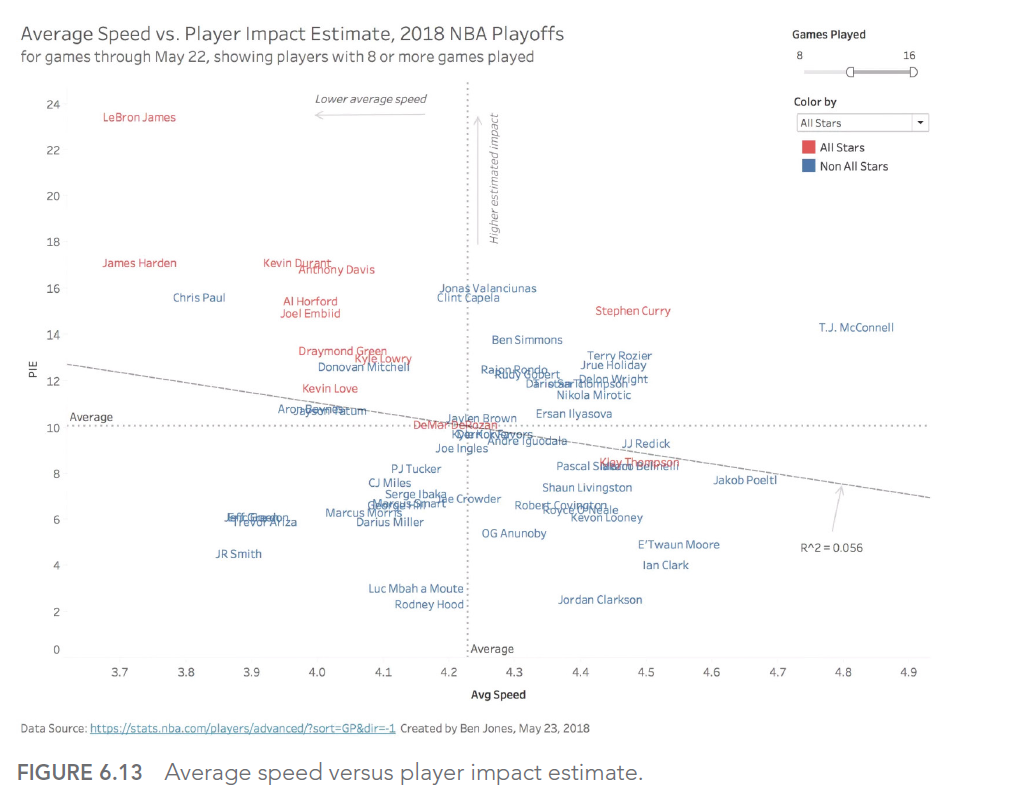
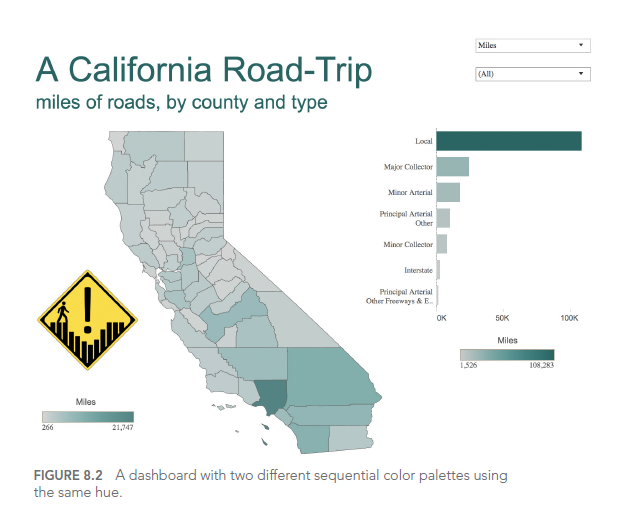
Considérons cet exemple de dashboard interactif sur les crimes à Orlando :
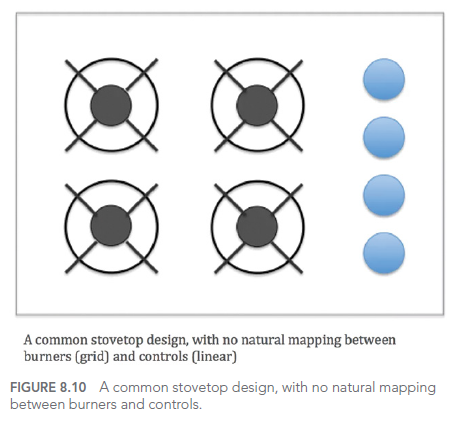
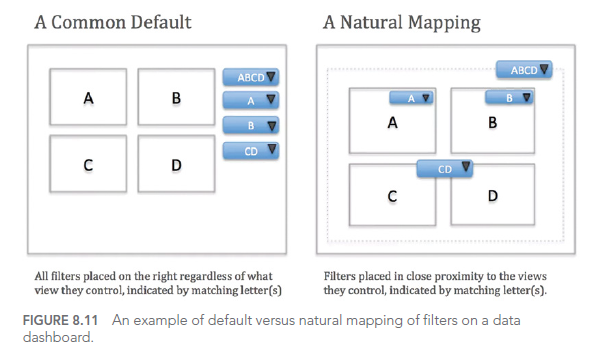
Ce dashboard offre de nombreuses options d’interaction, mais sans une conception soignée de l’interface utilisateur, il peut devenir écrasant et difficile à utiliser efficacement.
CONCLUSION
Dans ce dernier article de notre série, nous avons exploré le septième type d’erreur que nous pouvons rencontrer lorsque nous travaillons avec des données : les dangers du design. Nous avons vu comment les choix de couleurs, les opportunités manquées et les problèmes d’utilisabilité peuvent affecter l’efficacité de nos visualisations de données.
Au cours de cette série de sept articles, nous avons couvert un large éventail de pièges courants dans le travail avec les données, de la façon dont nous pensons aux données jusqu’à la manière dont nous les présentons. En étant conscients de ces pièges et en apprenant à les éviter, nous pouvons améliorer considérablement notre capacité à travailler efficacement avec les données et à communiquer des insights précieux.
Cette série d’articles est fortement inspirée par le livre « Avoiding Data Pitfalls – How to Steer Clear of Common Blunders When Working with Data and Presenting Analysis and Visualizations » écrit par Ben Jones, Founder and CEO de Data Literacy, édition WILEY. Nous vous recommandons vivement cette excellente lecture pour approfondir votre compréhension des pièges liés aux données et comment les éviter !
Vous trouverez tous les sujets abordés dans cette série ici : https://www.datanalysis.re/blog/business-intelligence/data-les-7-pieges-a-eviter-intro/