Lean UX Design : la clé pour révolutionner votre développement BI
Qu’est-ce que le Lean UX Design et pourquoi est-il crucial pour votre BI ?
Dans le monde dynamique de la Business Intelligence (BI), où la complexité des données rencontre les besoins évolutifs des utilisateurs, le Lean UX Design émerge comme une approche révolutionnaire. Cette méthodologie, centrée sur l’utilisateur, promet de transformer radicalement la façon dont nous concevons et développons des solutions BI.
Le Lean UX Design en bref
- Approche centrée utilisateur
- Itérations rapides et feedback continu
- Collaboration interfonctionnelle
- Réduction du gaspillage et optimisation des ressources
- Adaptation agile aux changements
Mais comment le Lean UX peut-il concrètement améliorer vos projets BI ? Plongeons dans les détails.
Les 5 Étapes Clés du processus Lean UX en BI
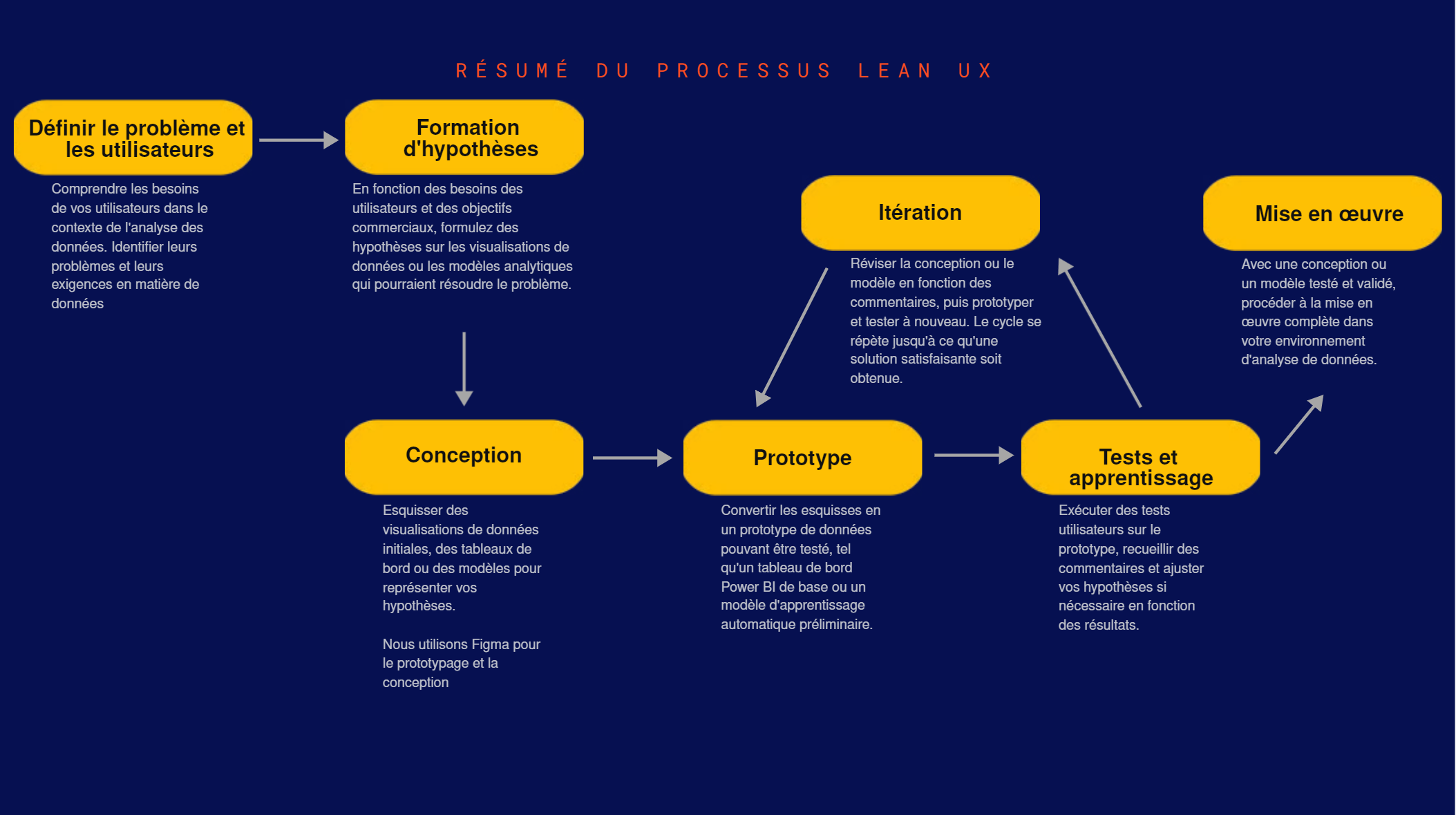
- Définition du problème et des utilisateurs : comprenez en profondeur les défis spécifiques de vos utilisateurs BI.
- Idéation et hypothèses : formulez des hypothèses sur les solutions potentielles.
- Prototypage rapide : créez des prototypes low-fidelity pour tester vos idées.
- Tests utilisateurs : obtenez rapidement des feedbacks pour valider ou invalider vos hypothèses.
- Itération et amélioration continue : affinez votre solution en fonction des retours utilisateurs.
Les avantages tangibles du Lean UX dans le développement BI
1. Réduction significative des coûts et du temps de développement
En identifiant rapidement ce qui fonctionne et ce qui ne fonctionne pas, le Lean UX permet d’économiser des ressources précieuses.
« Grâce à l’approche Lean UX de DATANALYSIS, nous avons réduit nos coûts de développement BI de 30% tout en augmentant la satisfaction utilisateur de 50%. »
– Marie Dupont, CIO, TechInnovate SA
2. Amélioration de l’expérience utilisateur et de l’adoption des outils BI
Des solutions BI conçues avec les utilisateurs, pour les utilisateurs, garantissent une meilleure adoption et utilisation.
3. Agilité et adaptabilité accrues face aux changements du marché
Dans un environnement BI en constante évolution, le Lean UX vous permet de pivoter rapidement et efficacement.
Voici les 5 étapes pour implémenter le Lean UX dans vos projets BI :
Adopter le Lean UX dans votre développement BI peut sembler intimidant.
Voici quelques étapes pour démarrer :
- Évaluez votre maturité UX actuelle
- Formez vos équipes aux principes du Lean UX
- Commencez par un projet pilote
- Mesurez et communiquez les résultats
- Étendez progressivement l’approche à d’autres projets
Etes-vous prêt pour le Lean UX ?
Nous vous aidons à le savoir !
CONCLUSION
Dans un monde où la data est reine, le Lean UX offre un moyen de transformer cette data en insights actionnables de manière plus rapide et plus précise que jamais. Pour les entreprises cherchant à tirer le meilleur parti de leurs investissements en BI, le Lean UX n’est pas seulement une option, c’est une nécessité compétitive.
Chez DATANALYSIS, nous sommes passionnés par l’application du Lean UX dans le développement BI. Notre équipe d’experts est prête à vous guider dans cette transformation pour optimiser vos processus, réduire vos coûts et améliorer significativement l’expérience utilisateur de vos solutions BI.