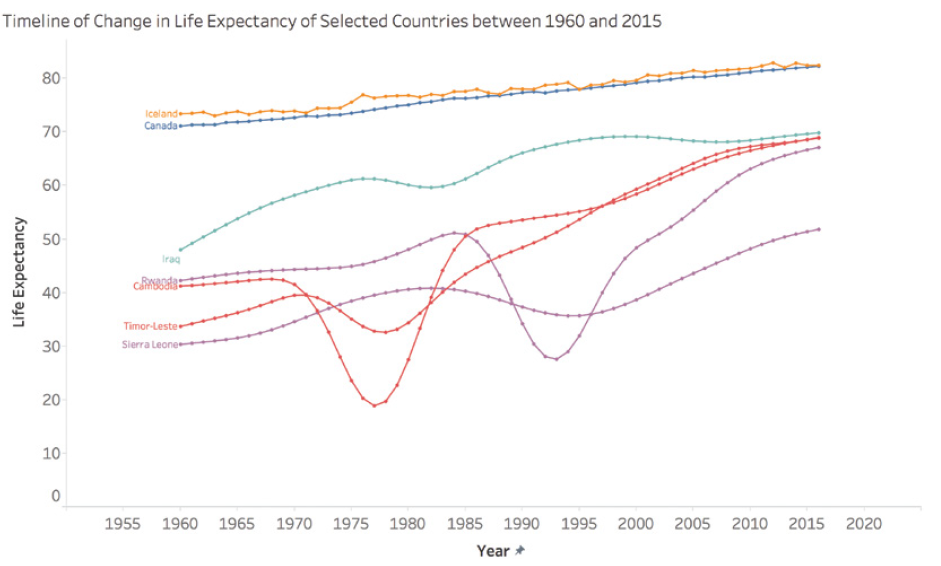
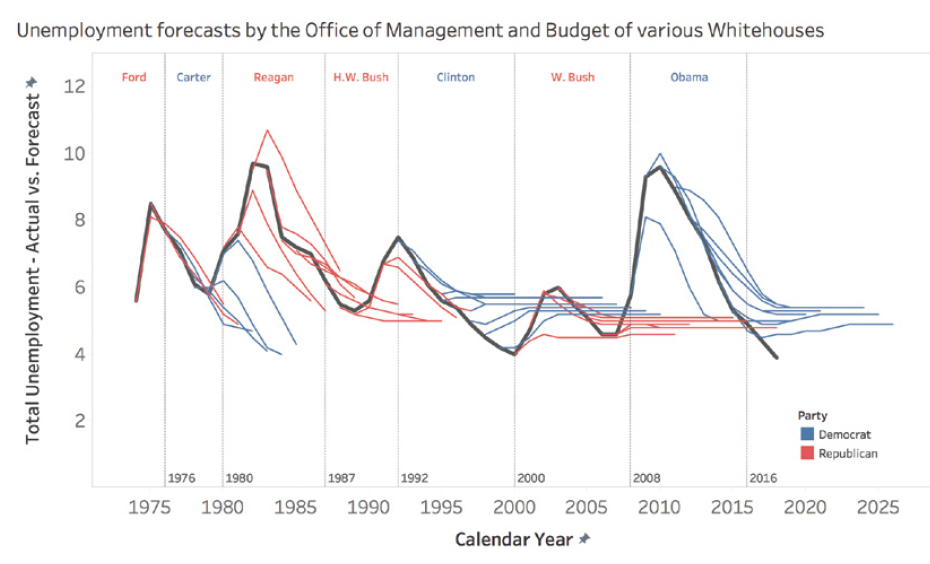
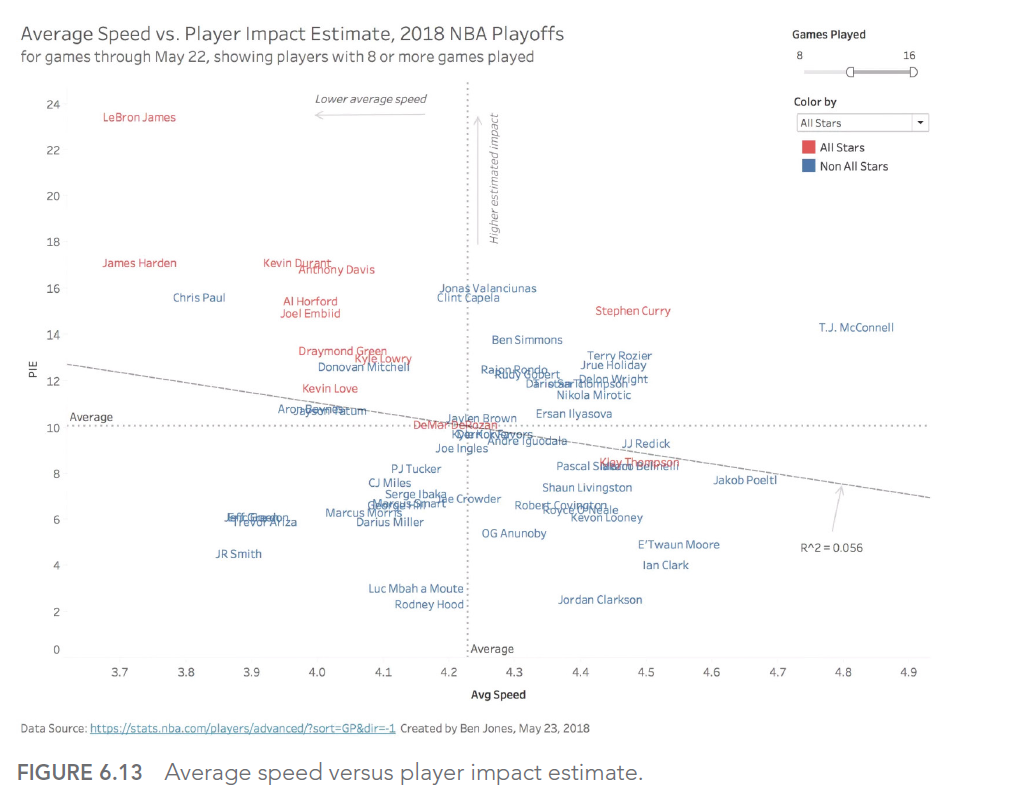
DATA: les 7 pièges à éviter, Ep 6/7 – Gaffes graphiques
Comment éviter les erreurs courantes dans la visualisation des données
La visualisation des données est un outil puissant pour communiquer des informations complexes de manière claire et concise. Cependant, elle peut aussi être source de nombreuses erreurs qui peuvent conduire à des interprétations erronées.
Dans cet épisode, nous explorerons les gaffes graphiques les plus courantes et comment les éviter.
Piège 6A: les graphiques trompeurs
L’un des pièges les plus courants dans la visualisation des données est la création de graphiques qui induisent en erreur, souvent involontairement. Cela peut se produire de plusieurs manières :
- Tronquer l’axe Y : En ne commençant pas l’axe Y à zéro, on peut exagérer visuellement les différences entre les valeurs.
- Choisir une échelle inappropriée : Une échelle mal choisie peut masquer ou exagérer des tendances importantes.
- Utiliser des graphiques en 3D : Les graphiques en 3D peuvent déformer la perception des proportions.
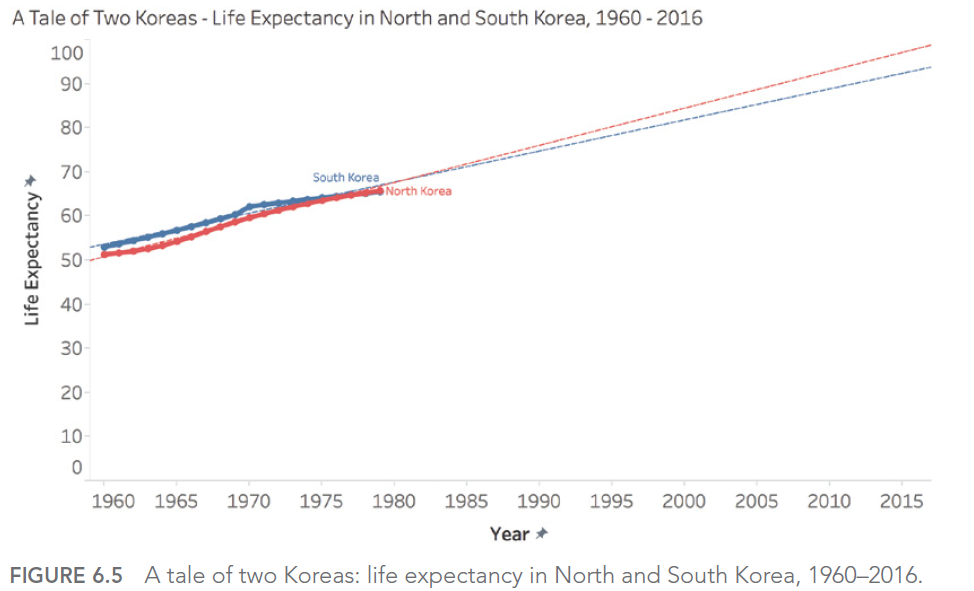
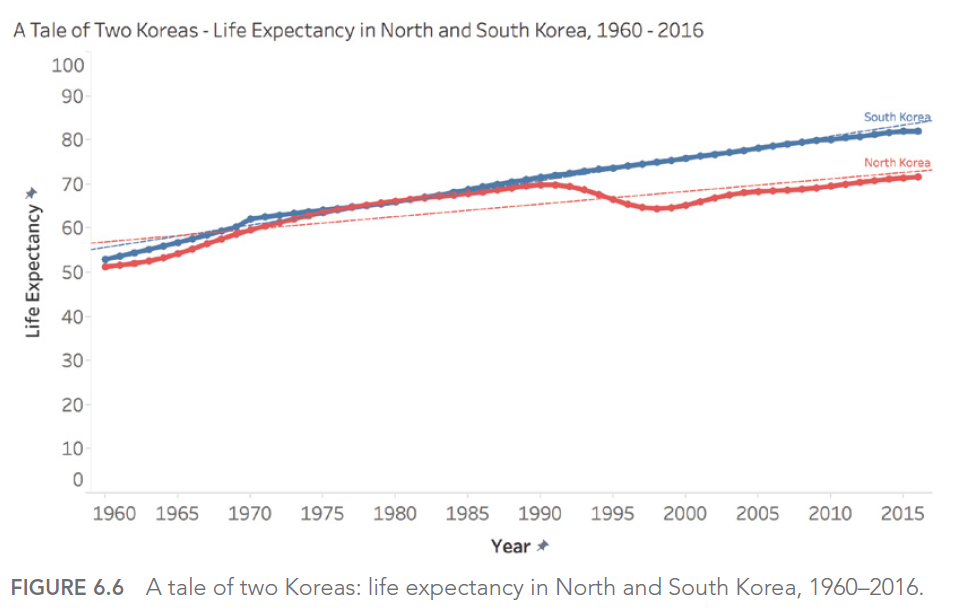
Par exemple, considérons ce graphique montrant les cas de crimes liés aux stupéfiants à Orlando :
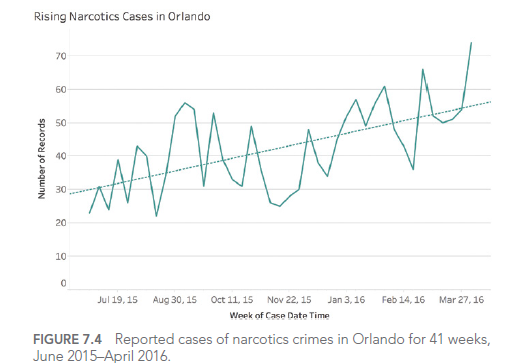
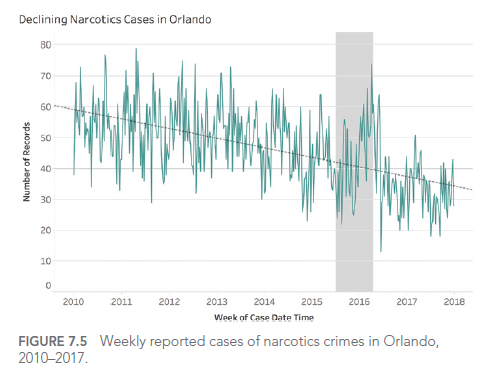
Ce graphique semble montrer une augmentation alarmante des crimes liés aux stupéfiants. Cependant, en examinant de plus près, on constate que l’axe Y ne commence pas à zéro, exagérant ainsi visuellement l’augmentation.
Piège 6B: le dogmatisme des données
Il est facile de tomber dans le piège du dogmatisme des données, en pensant qu’il n’existe qu’une seule « bonne » façon de visualiser les données. En réalité, le choix du type de graphique dépend du contexte, de l’audience et du message que l’on souhaite transmettre.
Par exemple, bien que les diagrammes circulaires soient souvent critiqués, ils peuvent être efficaces pour montrer des parts d’un tout, surtout lorsqu’il y a peu de catégories :
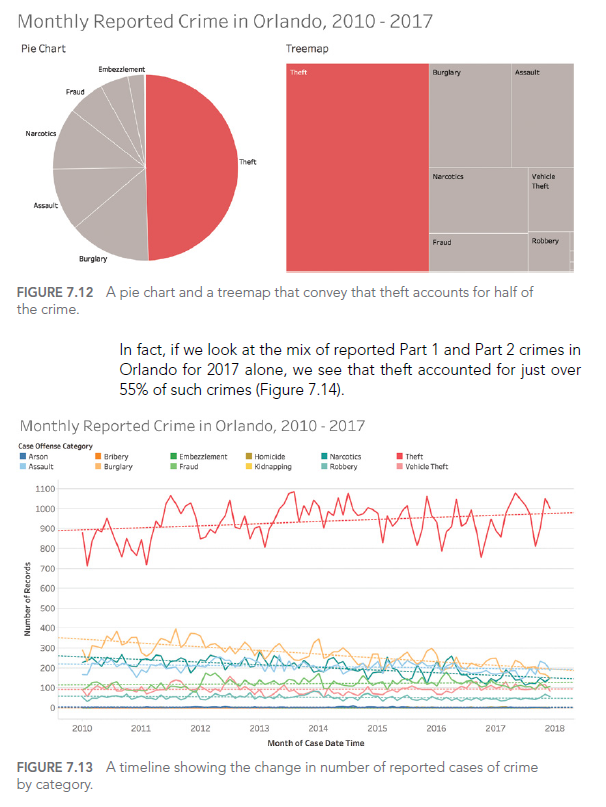
Ce diagramme circulaire montre clairement que le vol représente près de la moitié de tous les crimes signalés à Orlando.
Piège 6C: la fausse dichotomie optimisation/satisfaction
Dans la visualisation des données, on peut tomber dans le piège de penser qu’il faut toujours chercher la visualisation « optimale » au détriment de solutions « satisfaisantes ». En réalité, il est souvent plus pratique et efficace de trouver une visualisation qui répond suffisamment bien aux besoins, plutôt que de passer un temps excessif à chercher la perfection.
Par exemple, ce graphique à barres horizontales peut être « satisfaisant » pour montrer les types de crimes les plus courants, même s’il n’est pas nécessairement « optimal » :
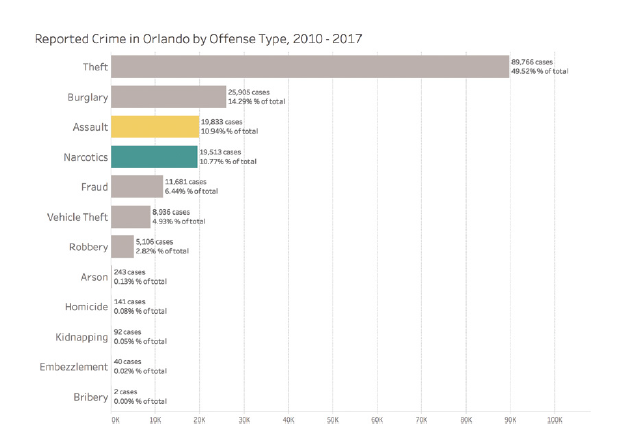
Ce graphique est facile à comprendre et fournit rapidement les informations essentielles, même s’il pourrait potentiellement être optimisé davantage.
CONCLUSION
Dans cet article, nous avons exploré le sixième type d’erreur que nous pouvons rencontrer lorsque nous travaillons avec des données : les gaffes graphiques. Nous avons vu comment éviter les graphiques trompeurs, le dogmatisme des données, et la fausse dichotomie entre optimisation et satisfaction.
Dans le prochain et dernier article de notre série, nous explorerons le 7ème type d’erreur : les dangers du design. Nous verrons comment les choix de design peuvent affecter la perception et l’interprétation des données visualisées.
Cette série d’articles est fortement inspirée par le livre « Avoiding Data Pitfalls – How to Steer Clear of Common Blunders When Working with Data and Presenting Analysis and Visualizations » écrit par Ben Jones, Founder and CEO de Data Literacy, édition WILEY. Nous vous recommandons vivement cette excellente lecture pour approfondir votre compréhension des pièges liés aux données et comment les éviter !
Vous trouverez tous les sujets abordés dans cette série ici : https://www.datanalysis.re/blog/business-intelligence/data-les-7-pieges-a-eviter-intro/