Offre d’Emploi : Consultant Sénior en Data Analytics – DATANALYSIS REUNION H.F – CDI
En recherche d’un nouveau challenge ?

🌟 Et si votre expertise en Data Analytics faisait la différence ?
Chez DATANALYSIS REUNION, nous transformons les données en leviers stratégiques pour nos clients. Pour accompagner notre croissance, nous recherchons notre prochaine pépite : un(e) Consultant(e) Sénior en Data Analytics passionné(e) par l’analyse de données, l’automatisation et la collaboration avec les métiers.
Votre mission ? Piloter des projets data ambitieux, garantir la qualité des données et concevoir des outils de reporting qui inspirent l’action.
🎯 Vos Missions Principales
- Automatiser et optimiser des outils de reporting pour nos clients (usage, parc, facturation, etc.).
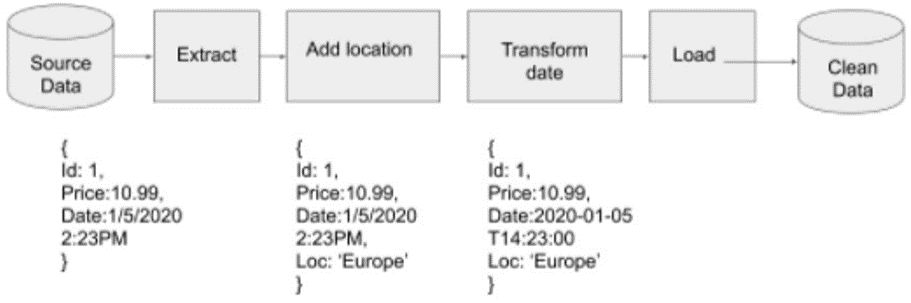
- Garantir la qualité et la fiabilité des données, de l’extraction à la visualisation.
- Collaborer au quotidien avec les équipes métiers et techniques pour traduire les besoins en solutions data concrètes.
- Créer des dashboards percutants (Power BI, Qlik) qui répondent aux enjeux business.
- Piloter des projets en méthodologie Agile (sprints mensuels) et assurer le transfert de connaissances.
🛠 Vos Atouts Techniques
- Maîtrise du SQL et des environnements S3, HDFS, GCP.
- Expérience en modélisation en étoile et en visualisation de données (Power BI, Qlik).
- Connaissance de GitLab pour le versioning et JIRA pour la gestion de projet.
- Familiarité avec Starburst et DBT pour la documentation des règles de gestion.
💡 Vos Soft Skills, notre différence
- Communication claire : Animer des réunions, comprendre les besoins métiers et présenter vos livrables avec pédagogie.
- Esprit d’équipe : Travailler main dans la main avec les équipes internes et externes.
- Résolution de problèmes : Identifier les anomalies, proposer des plans d’action et tester les solutions en environnement hors production.
- Rigueur organisationnelle : Estimer votre charge de travail et respecter les délais.
🌱 Pourquoi nous rejoindre ?
- Impact concret : Vos analyses influencent directement les décisions stratégiques de nos clients.
- Environnement stimulant : Méthodologies Agile, outils modernes (GitLab, Confluence) et projets variés.
- Équilibre vie pro/perso : Poste basé à La Réunion, avec une équipe soudée et bienveillante.
- Formation continue : Accès à des certifications et montées en compétences.
📌 Le Petit Plus
Vous aurez l’opportunité de former et accompagner les membres de l’équipe, tout en bénéficiant d’une autonomie dans la gestion de vos projets.
📅 Modalités
- Type de contrat : CDI
- Lieu : La Réunion.
- Salaire : A partir de 48k€/an selon profil et expérience.
💬 Vous vous reconnaissez ?
Envoyez-nous votre CV et une lettre de motivation à contact@datanalysis.re avec pour objet : « Candidature – Consultant Sénior Data Analytics ».
Prêt(e) à relever le défi ? Postulez dès maintenant et devenez un acteur clé de notre aventure data !
DATANALYSIS REUNION – Transformons les données en opportunités.