DATA: Les 7 pièges à éviter, Ep 5/7 – Aberrations analytiques
L’intuition et l’analyse ne sont pas mutuellement exclusives
Dans notre quête pour tirer le meilleur parti des données, nous tombons souvent dans le piège de considérer l’intuition et l’analyse comme des approches mutuellement exclusives. Cependant, comme nous le verrons dans cet épisode sur les aberrations analytiques, l’intuition joue un rôle crucial dans le processus d’analyse des données.
Piège 5A: la fausse dichotomie intuition/analyse
Il fut un temps où l’on entendait des publicités vantant le passage de l’intuition à l’analyse dans la prise de décision. Cette vision est erronée. L’intuition n’est pas obsolète à l’ère des données – elle est en réalité plus précieuse que jamais.
L’intuition est l’étincelle qui fait fonctionner le moteur de l’analyse. Elle nous aide à :
- Savoir POURQUOI les données sont importantes
- Comprendre CE QUE les données nous disent (et ne nous disent pas)
- Savoir OÙ chercher ensuite
- Savoir QUAND arrêter l’analyse et passer à l’action
- Savoir QUI a besoin d’entendre les résultats et COMMENT les communiquer
Piège 5B: les extrapolations exubérantes
Prédire l’avenir à partir des données peut être risqué. L’extrapolation des tendances actuelles peut conduire à des erreurs importantes si nous ne tenons pas compte des limites naturelles ou des changements potentiels.
Par exemple, si nous examinons l’espérance de vie en Corée du Nord et du Sud de 1960 à 1980, nous pourrions être tentés de prédire une augmentation continue et linéaire. Cependant, la réalité s’est avérée bien différente, notamment pour la Corée du Nord qui a connu une baisse significative dans les années 1990.
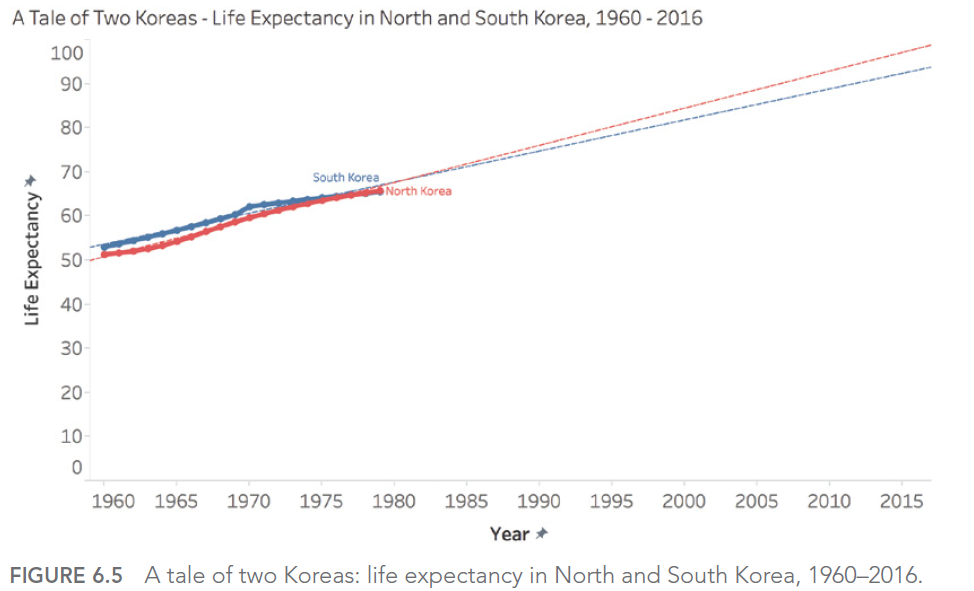
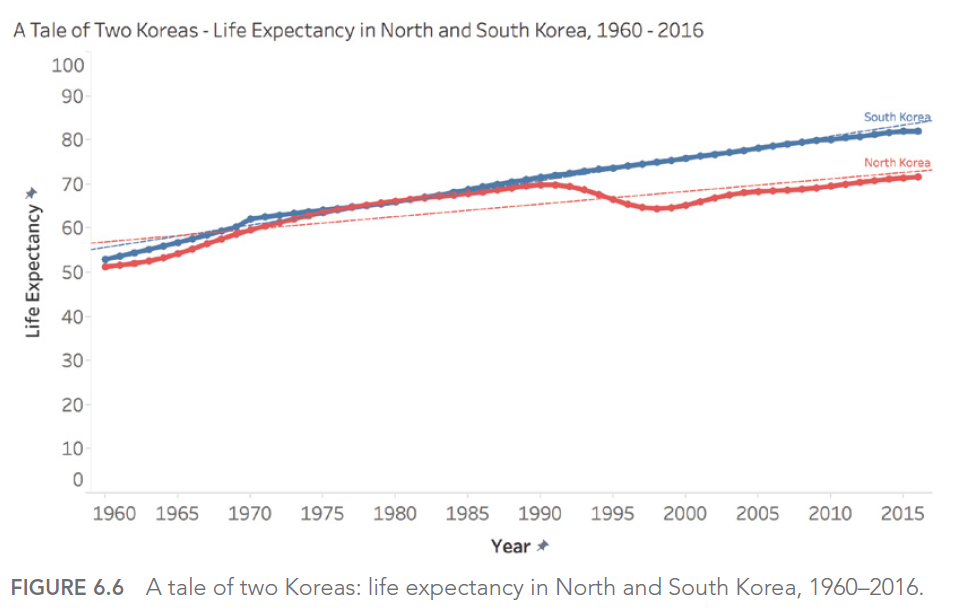
Piège 5C: les interpolations mal avisées
Lorsque nous travaillons avec des données chronologiques, nous devons être prudents dans nos interprétations entre les points de données. Un graphique en pente simple reliant deux points dans le temps peut masquer des fluctuations importantes entre ces points.
Par exemple, considérons l’espérance de vie dans certains pays entre 1960 et 2015. Un simple graphique en pente montrant le changement entre ces deux années pourrait donner l’impression d’une augmentation régulière et constante. Cependant, cette représentation simplifiée masquerait des périodes de conflit, de difficultés économiques ou de progrès rapides en matière de santé publique qui ont eu un impact significatif sur l’espérance de vie au fil des années.
Prenons le cas du Cambodge, du Timor-Leste, de la Sierra Leone et du Rwanda. Un graphique en pente simple montrerait une augmentation de l’espérance de vie entre 1960 et 2015, mais occulterait complètement les périodes tragiques de guerre et de génocide que ces pays ont connues. Par exemple, l’espérance de vie au Cambodge est tombée à moins de 20 ans en 1977 et 1978, un fait crucial qui serait complètement ignoré dans une simple interpolation entre 1960 et 2015.
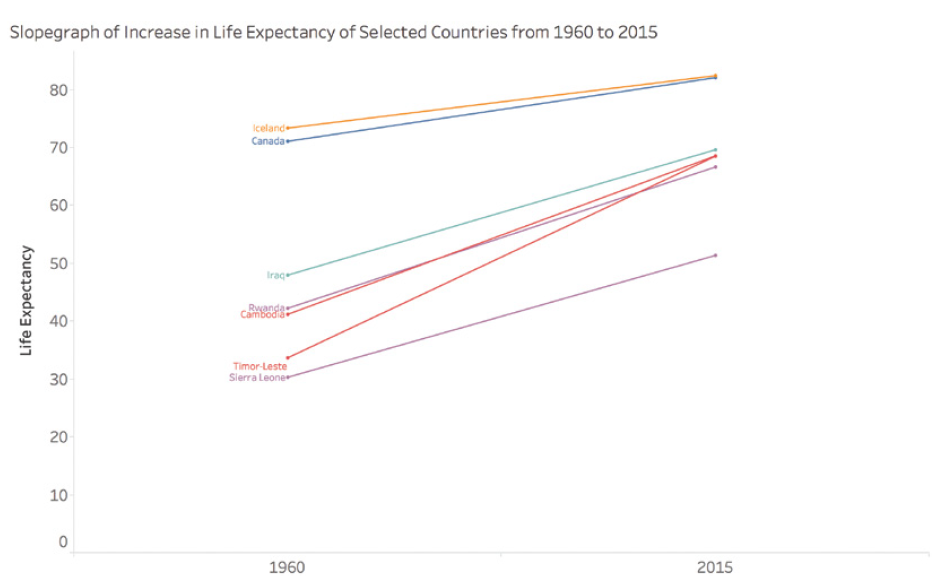
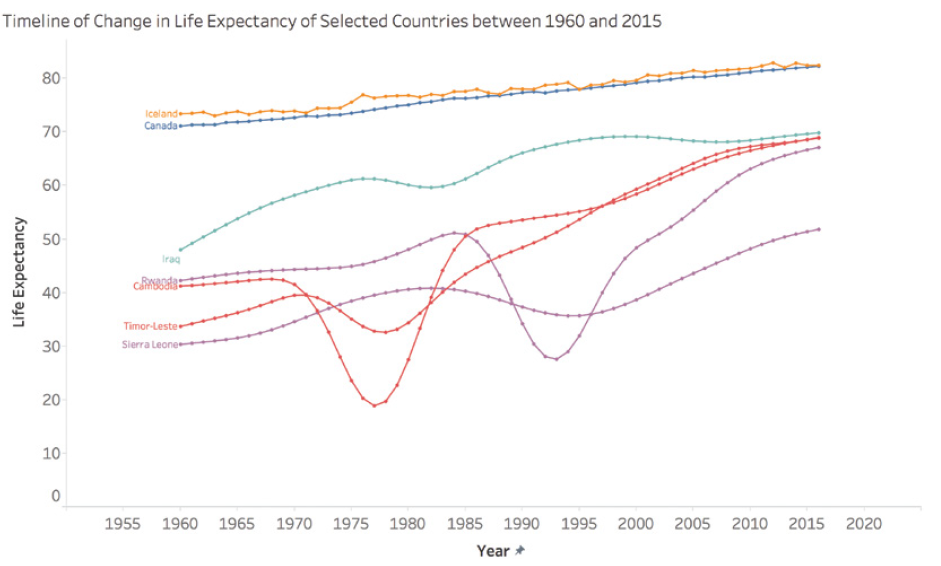
Ce graphique montre l’évolution réelle de l’espérance de vie dans ces pays, révélant les fluctuations dramatiques masquées par une simple interpolation linéaire.
Piège 5D: les prévisions farfelues
Les prévisions, en particulier celles à long terme, peuvent être particulièrement sujettes aux erreurs. Un exemple frappant est celui des prévisions de chômage faites par différentes administrations présidentielles américaines. Ces prévisions ont tendance à montrer un retour rapide à un taux « normal » de 4 à 6%, indépendamment de la situation économique réelle.
Ce phénomène s’explique par plusieurs facteurs. Tout d’abord, il y a une pression politique pour présenter des perspectives optimistes. Ensuite, il existe une tendance naturelle à supposer que les situations extrêmes ou inhabituelles se corrigeront d’elles-mêmes rapidement. Enfin, les modèles de prévision sont souvent basés sur des données historiques et peuvent ne pas bien prendre en compte les changements structurels de l’économie.
Par exemple, lors de la crise financière de 2008, les prévisions de chômage faites juste avant ou au début de la crise n’ont pas réussi à anticiper l’ampleur et la durée de l’augmentation du chômage. De même, les prévisions faites au plus fort de la crise ont souvent sous-estimé le temps nécessaire pour que le taux de chômage revienne à des niveaux pré-crise.
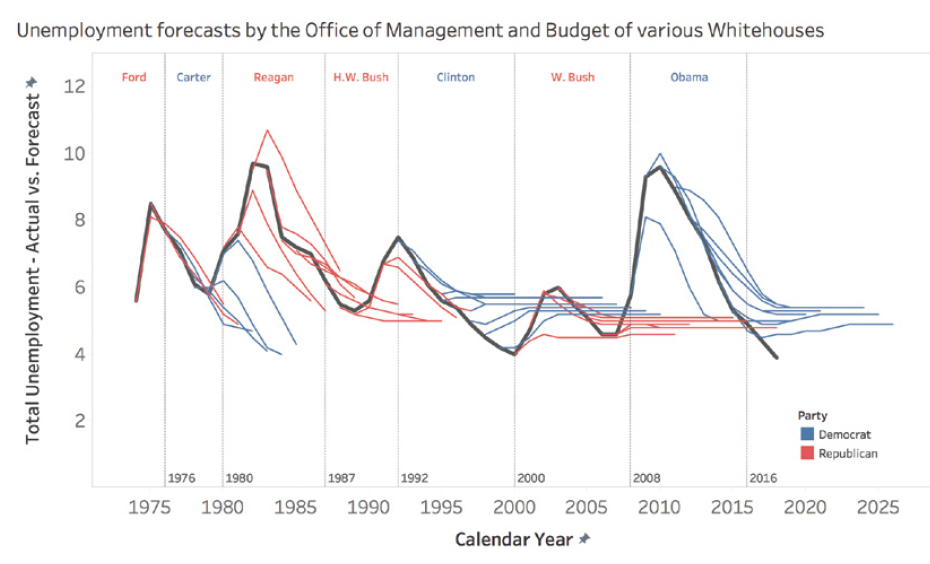
Ce graphique montre comment différentes administrations présidentielles ont systématiquement prévu un retour rapide à un taux de chômage « normal », même face à des réalités économiques très différentes.
Piège 5E: les mesures moroniques
Il est crucial de s’assurer que les mesures que nous utilisons sont pertinentes et significatives. Trop souvent, nous nous concentrons sur des mesures faciles à obtenir plutôt que sur celles qui sont vraiment importantes pour comprendre un phénomène ou prendre des décisions.
Dans le domaine du sport, par exemple, de nombreuses mesures traditionnelles peuvent être trompeuses. Prenons le cas du basket-ball professionnel : la vitesse moyenne d’un joueur sur le terrain peut sembler être une mesure intéressante, mais elle ne reflète pas nécessairement l’impact réel du joueur sur le jeu.
LeBron James, l’un des meilleurs joueurs de tous les temps, a été critiqué lors des playoffs de 2018 pour avoir la vitesse moyenne la plus basse sur le terrain. Cependant, cette mesure ne tenait pas compte de son impact réel sur le jeu, mesuré par des statistiques plus pertinentes comme le Player Impact Estimate (PIE).
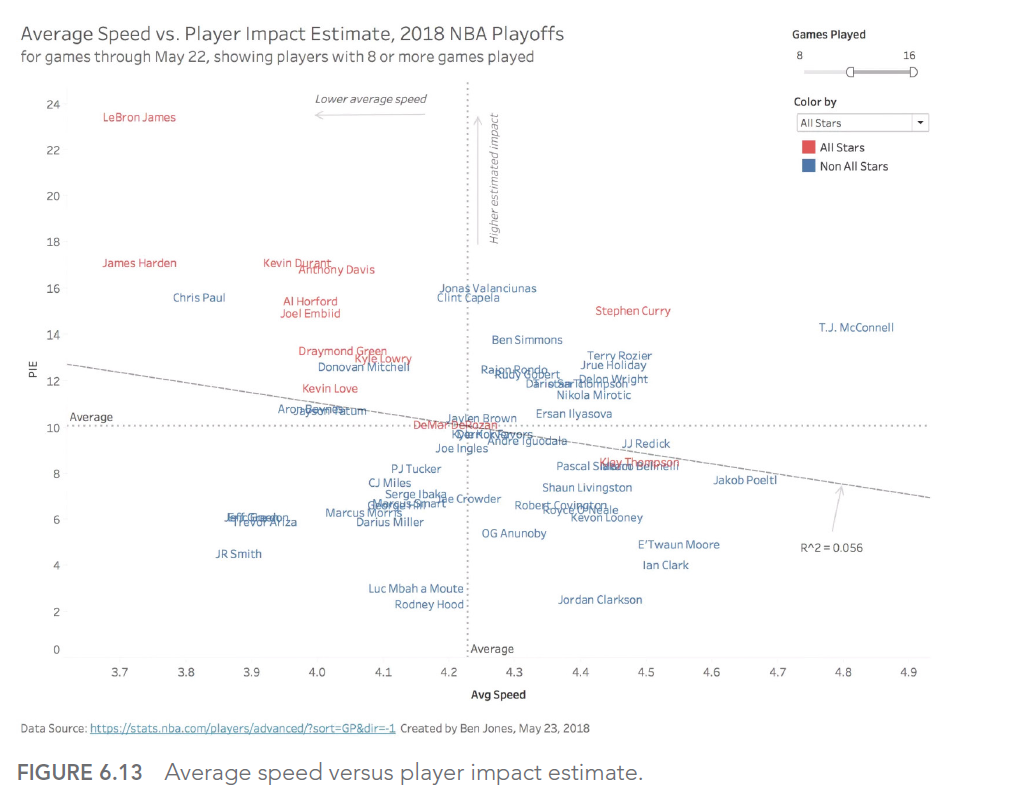
Ce graphique montre la relation entre la vitesse moyenne et le PIE des joueurs de NBA. On peut voir que LeBron James (point en haut à gauche) a un PIE très élevé malgré une vitesse moyenne relativement basse, illustrant pourquoi la vitesse moyenne seule est une mesure inadéquate de la performance d’un joueur.
Ce cas illustre l’importance de choisir des mesures qui reflètent réellement ce que nous cherchons à évaluer, plutôt que de nous contenter de mesures faciles à obtenir mais potentiellement trompeuses.
CONCLUSION
Dans cet article, nous avons exploré le cinquième type d’erreur que nous pouvons rencontrer lorsque nous utilisons les données pour éclairer le monde qui nous entoure : les aberrations analytiques. Nous avons vu comment l’intuition et l’analyse peuvent travailler de concert, et comment éviter les pièges des extrapolations exubérantes, des interpolations mal avisées, des prévisions farfelues et des mesures moroniques.
Dans le prochain article, nous allons explorer le 6ème type d’erreur de notre série : les gaffes graphiques. Nous verrons comment les erreurs dans la visualisation des données peuvent conduire à des interprétations erronées et des décisions mal informées.
Cette série d’articles est fortement inspirée par le livre « Avoiding Data Pitfalls – How to Steer Clear of Common Blunders When Working with Data and Presenting Analysis and Visualizations » écrit par Ben Jones, Founder and CEO de Data Literacy, édition WILEY. Nous vous recommandons vivement cette excellente lecture pour approfondir votre compréhension des pièges liés aux données et comment les éviter !
Vous trouverez tous les sujets abordés dans cette série ici : https://www.datanalysis.re/blog/business-intelligence/data-les-7-pieges-a-eviter-intro/