Pour rester dans cette métaphore de la construction, si des problèmes de cette nature existent, ceux-ci seront cachés et peu visibles dans l’édifice final. Il est donc nécessaire d’apporter un soin particulier lors des étapes de collecte, de traitement, de nettoyage des données. Ce n’est pas pour rien que l’on estime que 80% du temps passé sur un projet de data science est consommé sur ce type de tâches.
Afin d’éviter de tomber dans ce piège et de limiter la charge nécessaire à la réalisation de ces opérations qui peuvent être fastidieuses, il faut accepter trois principes fondamentaux :
Accepter ces principes n’enlève pas l’obligation de passer par ce travail préalable à toute analyse mais, bonne nouvelle : savoir identifier ces risques et apprendre au fur et à mesure de nos projets, permet de limiter la portée de ce deuxième obstacle.
Les données sont sales. Je dirais même plus, toutes les données sont sales (voir premier principe énoncé précédemment), problématique de formatage, de saisie, d’unités incohérentes, de valeurs NULL etc.
Quelques exemples de ce piège sont très connus
Nous pouvons citer le crash de la sonde Mars Climate Orbiter de la NASA en 1999, par exemple. Une erreur à 125 millions de dollars qui a été causée par un double système d’unité : unités impériales et unités issues du système métriques. Cela a occasionné un calcul erroné qui a joué sur la puissance envoyée aux propulseurs de la sonde et à la destruction de celle-ci.
Heureusement, toutes les erreurs de cette nature ne vont pas nous coûter autant d’argent ! Mais elles auront malgré tout des impacts significatifs sur les résultats et le ROI des analyses que nous sommes amenés à mener.
Ainsi, chez DATANALYSIS, nous menons actuellement plusieurs projets spécifiquement sur la qualité de données dans le cadre de sujet de DATA Marketing et nous faisons face à deux types de sujet :
-Normalisant les champs (numéro de téléphone, email etc.) : +262 692 00 11 22 / 00262692001122 / 06-92-00-11-22 correspondent à la même ligne et nous pouvons grâce à des traitements adaptés automatiser une grande partie de ce travail ;
– Complétant des champs vides grâce aux autres données présentes dans la table. Nous pouvons par exemple déduire le pays de résidence à partir des indicatifs téléphoniques, des codes postaux, des villes etc.
-Cherchant à identifier grâce à des règles adaptées des lignes potentiellement identiques. Deux enregistrements ayant le même mail, ou le même numéro de téléphone, ou le même identifiant pour les entreprises ;
-Cherchant grâce à des algorithmes de calcul de distance à définir les valeurs proches en termes d’orthographe, de prononciation, de caractères communs etc.
Au regard de ces quelques exemples et de nos propres expériences, il est possible de constater que ce type d’erreur provient principalement des processus de saisie, de collecte ou de « scrapping » des données qu’ils soient mis en œuvre automatiquement ou par des humains. Ainsi outre les solutions que l’on peut mettre en œuvre dans les traitements de préparations de données, l’amélioration de ces étapes préalables permettra également d’améliorer grandement la qualité des données à traiter, et cela passe par l’éducation, la formation et la définition de règles et de normes clairement connues et partager (la data gouvernance n’est jamais loin).
Enfin, il convient également de se demander au regard de cette étape, quand nous pouvons considérer comme suffisamment propre. En effet, nous pouvons toujours faire plus et mieux, mais souvent les coûts engendrés peuvent dépasser les retours espérés.
Dans le monde informatique, il existe une image visant à résumer ce type de problématique :
Souvent l’erreur se situe entre l’écran et le siège !
Et oui, même les meilleurs data scientists, data analysts ou data engineers peuvent se tromper dans les étapes de nettoyage, de transformation et de préparation des données.
Fréquemment, nous manipulons plusieurs fichiers issus de différentes sources, de différentes applications, ce qui multiplie les risques liés aux problématiques de données sales et les risques lors de la manipulation des fichiers en eux-mêmes :
Et ce problème peut être également rendu plus complexe en fonction des outils utilisés dans le cadre de nos analyses :
Il s’agit dans ce cas souvent de contraintes techniques liées au métier même de préparation de données et prendre le temps d’appréhender les risques et les processus en place permettra de gagner un temps important sur la mise à disposition d’analyse de données fiables et performantes.
Dans le prochain article, nous allons explorer le 3ème type d’obstacle que nous pouvons rencontrer lorsque nous utilisons les données pour éclairer le monde qui nous entoure : Les Erreurs Mathématiques
Cet article est inspiré fortement par le livre ” Avoiding Data pitfalls – How to steer clear of common blunders when working with Data and presenting Analysis and visualisation” écrit par Ben Jones, Founder and CEO de Data Litercy, édition WILEY. Nous vous recommandons cette excellente lecture!
Pour retrouver l’intégralité des sujets qui seront abordés au cours de cette série par ici : https://www.datanalysis.re/blog/business-intelligence/data-les-7-pieges-a-eviter-intro/

Dans le monde de la donnée, il s’agit d’un sujet central et critique. En effet, nous avons été familiarisés avec le processus de transformation de la donnée, en informations, en connaissance et en élément de sagesse :
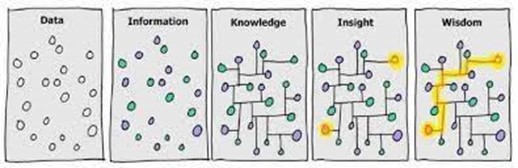
Ici le problème trouve sa source dans la manière dont nous considérons notre point de départ : les données ! En effet, l’utilisation de celle-ci et sa transformation au cours des étapes suivantes relèvent de procédés et processus conscients et maîtrisés :
==>Je nettoie ma donnée, la traite dans un ETL / ELT, la stocke, la visualise, communique mon résultat et le partage etc. Cette maîtrise nous donne le contrôle sur la qualité des étapes. Toutefois, on aura tendance à se lancer dans ce travail de transformation de notre ressource primaire en omettant un point crucial, source de notre premier obstacle :
LA DONNEE N’EST PAS UNE REPRESENTATION EXACTE DU MONDE REEL !
En effet, il est excessivement simple de travailler avec des données en pensant aux données comme étant la réalité elle-même et pas comme des données collectées à propos de la réalité. Cette nuance est primordiale :
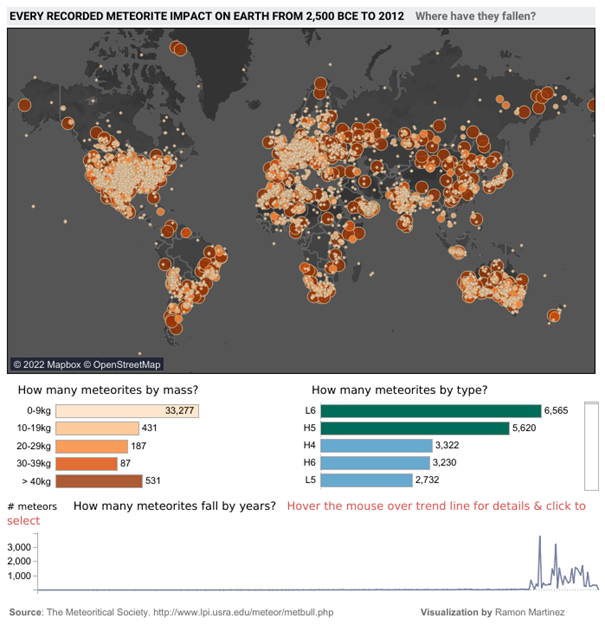
Regardons ensemble ce dashboard présentant l’ensemble des impacts de météorites sur la Terre entre -2500 et 2012. Pouvez vous identifiez ce qu’il y a d’étranges ici ?
Les météorites semblent avoir évité soigneusement certaines parties de la planète, une large part de l’Amérique du Sud, de l’Afrique, de la Russie, du Groenland etc. Et si l’on se concentre sur le graphique montrant le nombre de météorites par années, que celles-ci ont eu tendance à tomber plutôt dans les 50 dernières années (et presque pas sur l’ensemble de la période couvrant -2055 à 1975).
Est-ce qu’il s’agit bien de la réalité ? Ou plutôt de défauts dans la manière dont les données ont été collectées
Parfois, la cause de cet écart entre la donnée et la réalité peut être expliqué par un défaut du matériel de collecte. Malheureusement, tout ce qui est fabriqué par un être humain en ce bas monde est susceptible d’être défaillant. Cela vaut pour les capteurs et les instruments de mesure évidemment.
Que s’est-il passé les 28 et 29 avril 2014 sur ce pont ? Il semblerait qu’il y ait un énorme pic de traversée du pont de Fremont par des vélos mais uniquement dans un seul sens (courbe bleue).
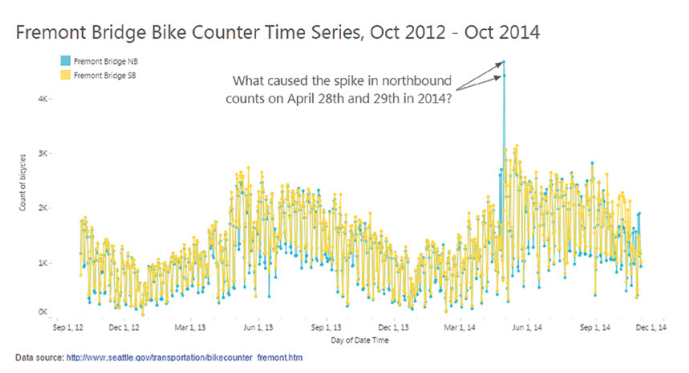
On pourrait penser qu’il s’agissait d’une magnifique journée d’été et que tout le monde est passé sur le pont en même temps ? D’une course de vélos n’empruntant celui-ci que dans un sens ? Que tous les pneus de toutes les personnes ayant traversé le pont à l’aller ont crevé avant le retour ?
Plus prosaïquement, il s’avère que le compteur bleu avait un défaut ces jours précis et ne comptait plus correctement les traversées du pont. Un simple changement de batterie et du capteur et le problème a été résolu.
Maintenant, posez vous la question du nombre de fois où vous avez pu être induit en erreur par des données issues d’un capteur ou d’une mesure défaillante sans que cela n’ait été perçu ?
Et oui, nos propres biais humains ont un effet important sur les valeurs que nous enregistrons lors de la collecte d’informations. Nous avons par exemple tendance à arrondir les résultats des mesures :
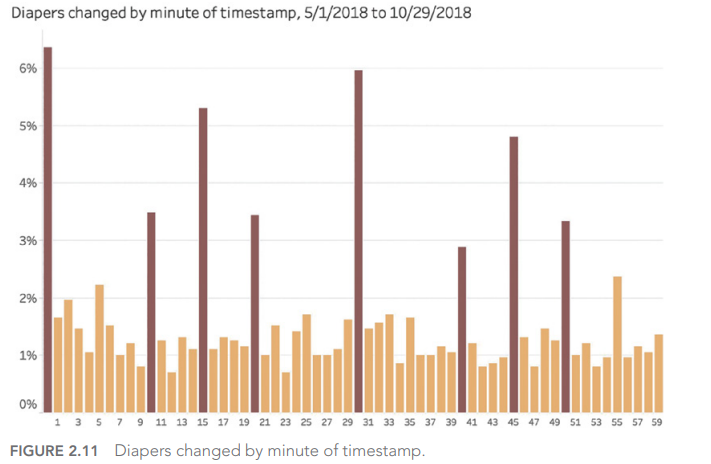
Si l’on s’en fit à ses données, le changement des couches se fait plus régulièrement toutes les 10 minutes (0, 10, 20, 30, 40, 50) et parfois sur certains quarts d’heure (15, 45). Cela serait assez incroyable n’est-ce pas ?
Il s’agit bien d’un récit incroyable. En effet, il faut se pencher ici sur la manière dont les données ont été collectées. En tant qu’être humain, nous avons cette tendance à arrondir les informations lorsque nous les enregistrons, notamment lorsque nous regardons une montre ou une horloge : pourquoi ne pas indiquer 1:05 lorsqu’il est 1 :04 ? ou encore plus simple 1:00 car c’est plus simple encore ?
On retrouvera ce type de simplification humaine dans toutes les collectes de mesures : poids, tailles, etc.
Dernier exemple que nous souhaitons mettre en avant ici, et ce que l’on appelle l’effet « Cygne Noir ». Si nous pensons que les données dont nous disposons sont une représentation exacte du monde qui nous entoure et que nous pouvons en sortir des affirmations à graver dans le marbre ; alors nous nous trompons fondamentalement sur ce qu’est une donnée (cf. précédemment).
Le meilleur usage des données est d’apprendre ce qui n’est pas vrai à partir d’une idée préconçue et de nous guider dans les questions que nous devons nous poser pour en apprendre plus ?
Mais revenons à notre cygne noir :
Avant la découverte de l’Australie, toutes les observations de cygne jamais faite pouvaient conforter les européens que tous les cygnes étaient blancs, à tort ! En 1697, l’observation d’un cygne noir a remis intégralement en question cette préconception commune.
Et le lien avec les données ? De la même manière que l’on aura tendance à croire qu’une observation répétée est une vérité générale ; à tort ; on peut être amener à inférer que ce que nous voyons dans les données que nous manipulons peut s’appliquer de manière générale au monde qui nous entoure et à toute époque. C’est une erreur fondamentale dans l’appréciation des données.

Il suffit pour cela d’une légère gymnastique mentale et d’un peu de curiosité :
Dans le prochain article, nous allons explorer le 2ème type d’obstacle que nous pouvons rencontrer lorsque nous utilisons les données pour éclairer le monde qui nous entoure : Les Erreurs Techniques
Pour retrouver l’intégralité des sujets qui seront abordés au cours de cette série par ici : https://www.datanalysis.re/blog/business-intelligence/data-les-7-pieges-a-eviter-ep-1-7/

De nos jours, la donnée est partout, mise en avant dans tous les nouveaux projets et toutes les stratégies d’entreprise. C’est la clé de la performance dans une époque pleine d’incertitudes. Chez Datanalysis, nous en sommes les premiers convaincus car il s’agit d’un outil puissant et accélérateur de performance… lorsque celle-ci est bien utilisée, bien comprise et bien maîtrisée !
Dans cette nouvelle série d’articles, nous allons donc parler du grand méchant loup ; du diable qui se cache dans le détail (ou qui se révèle parfois au grand jour) et évoquer avec vous les 7 principaux types de pièges posés par la donnée et son usage. Nous tâcherons autant que possible de les illustrer par un exemple de notre propre expérience car en tant qu’experts nous avons eu la chance de faire face dans nos missions à chacun d’entre eux…

Remarque : Ces pièges sont ceux évoqués dans le livre de Ben Jones, « 7 data pitfalls » que nous vous conseillons chaudement !
Trêve de suspense, dévoilons à présent les 7 familles de péchés capitaux de la DATA que nous allons explorer plus en détail pendant les 7 prochaines semaines :
Souvent nous utilisons les données avec le mauvais état d’esprit ou des préconceptions erronées. Ainsi, si nous nous attaquons à un projet d’analyse en pensant que les données sont une représentation parfaite de la réalité ; que nous établissons des conclusions définitives sur la base de prédiction sans les remettre en question ; ou que nous cherchons dans les informations disponibles tout ce qui pourrait confirmer une opinion déjà faite ; alors nous pouvons créer des erreurs critiques dans les fondations même de ces projets.
Les enjeux techniques et technologies sont souvent une source importante d’erreurs dans le monde de la donnée. Une fois que l’on a identifié les informations dont on a besoin se dresse devant nous une série importante d’obstacles à franchir. Est-ce que mes capteurs sont fonctionnels ? Est-ce que mes traitements ne génèrent pas des doublons ? Est-ce que mes données sont propres ou bien mises à niveau ? Des enjeux complexes dans nos projets ! En effet, ne dit-on pas qu’un data analyst passe la majeure partie de son temps et de son énergie à préparer et nettoyer ses données ?
Et voilà, vous savez maintenant à quoi vous servent vos cours de mathématiques de vos années d’école, de collège et de lycée ! Il y en a pour tous les niveaux et pour tous les goûts ! Que celui qui n’a jamais associé des données qui ne sont pas au même niveau de détail, qui ne s’est pas trompé dans le calcul de ses ratios, ou qui n’a pas oublié qu’il ne faut pas mélanger carottes et bananes, nous jette la première pierre !
Comme le dit l’adage, « Il y a des mensonges, des maudits mensonges et des statistiques ». Il s’agit là du piège le plus complexe à appréhender car de sacrées compétences sont nécessaires pour en bien comprendre les enjeux. Toutefois, dans un monde où le machine learning, le datamining et l’IA sont rois, c’est une famille d’erreurs qui ne fait que devenir plus fréquente !
Les mesures de tendance centrale ou de variation que nous utilisons nous égarent-elles ? Est-ce que les échantillons sur lesquels nous travaillons sont représentatifs de la population que nous voulons étudier ? Est-ce que nos outils de comparaison sont valides et significatifs statistiquement ?
Et voilà, vous savez maintenant à quoi vous servent vos cours de mathématiques de vos années d’école, de collège et de lycée ! Il y en a pour tous les niveaux et pour tous les goûts ! Que celui qui n’a jamais associé des données qui ne sont pas au même niveau de détail, qui ne s’est pas trompé dans le calcul de ses ratios, ou qui n’a pas oublié qu’il ne faut pas mélanger carottes et bananes, nous jette la première pierre !
Règle d’or: nous sommes tous des analystes (que l’on porte ce titre ou non).
Dès lors que nous utilisons des données pour prendre des décisions alors nous sommes des analystes et nous sommes donc sujets à prendre des décisions sur des analyses aberrantes. Connaîssez-vous par exemple les ‘vanity metrics’ ? Ou avez-vous déjà fait des extrapolations qui ne font aucun sens au regard des données utilisées ?
Contrairement aux erreurs statistiques ou aux aberrations analytiques, les gaffes graphiques sont bien connues et facilement identifiables. Pourquoi ? Parce que celles-ci se voient (et souvent de loin). Avons-nous choisi un type de graphique adapté à notre analyse ? Est-ce que l’effet que je souhaite montrer est clairement visible ?
Quelle différence avec les gaffes graphiques ?
Ici nous parlons du design général du produit final et des interactions que nous avons définies dans celui-ci pour que l’auditoire que nous cherchons à convaincre aient l’expérience la plus ergonomique et esthétique possible ! Est-ce que le choix des couleurs qui a été fait rend l’analyse confuse ou au contraire la simplifie ? Est-ce que nous avons utilisé de notre créativité pour rendre nos dashboards agréables à l’œil et avons-nous utilisé l’esthétique pour apporter de l’impact à l’analyse qui est faite ? Est-ce que le produit final est simple à utiliser, ergonomique ou les interactions sont complexes et poussives ?


Accompagner nos clients dans leurs projets de transformation numérique et d’analyse de données.
Partenaires majeurs des entreprises de l’océan Indien pour leurs projets autour de la données, DATANALYSIS dans le cadre de son expansion recrute un Consultant Sénior BI & Data Visualisation.
Véritable actif stratégique des entreprises, la donnée est aujourd’hui au cœur des enjeux de performance économique et concurrentielle. Nos équipes maîtrisent parfaitement son cycle de vie et les leviers pour que cette donnée devienne une information précieuse. Pour nous aider à aller encore plus loin et pour offrir une expertise additionnelle à nos clients, nous recherchons un profil alliant expertises technologiques et savoir-faire métier pour participer à la réalisation des projets de Business Intelligence de nos clients.
Intégré à une équipe de 8 consultants sénior spécialisés en BI Self-Service, en Data visualisation, Machine Learning et IA, votre poste vous amènera à :
• Participer au cadrage des besoins des entreprises,
• Être force de proposition quant à la réalisation de solutions décisionnelles, en mode Agile,
• Proposez des analyses visuelles claires et génératrices de valeur pour leurs utilisateurs,
• Exploiter vos compétences techniques dans le traitement et la valorisation des données.
Vous aimez relever les nouveaux défis et vous savez faire preuve d’engagement pour réussir et évoluez aisément dans un environnement dynamique.
Vous vous intéressez naturellement à vos clients pour savoir dans quelle mesure vous pouvez les aider à résoudre leurs problèmes.
Vous possédez un bon esprit d’analyse et de synthèse, un excellent relationnel.
VOUS PROFITEREZ PLEINEMENT DE CE POSTE SI…
• Vous disposez d’une forte appétence pour les nouvelles technologies.
• Vous avez des compétences avancées dans l’une ou plusieurs des technologies suivantes :
o 3-5 ans d’expérience minimum sont attendus en développement sur Qlikview/Qliksense
o Des compétences Tableau Software sont un vrai plus
• Vous faites également preuve également de capacités de gestion de projet, de recueil de besoin,
La curiosité, l’intérêt pour le monde de la donnée, de la data visualisation et de l’IA sont des vraies plus.
Enfin, et surtout, vous êtes chaleureux, souriant, dynamique et vous avez un bon esprit d’équipe. Vous aimez rendre service en apportant du soin à la qualité de votre travail.
OÙ TRAVAILLEREZ-VOUS ?
Le poste est basé à la Saline, commune de Saint Paul, la Réunion. Des déplacements sur toute l’île, et potentiellement sur l’île Maurice et Madagascar sont à prévoir.


Encore un mot tendance ? On ne partage pas cet avis !
Bien que l’ingénierie des données ne soit pas un domaine nouveau, cette discipline semble être aujourd’hui sortie de l’ombre et propulsée au-devant de la scène.
Nous avions justement envie de parler « métier » comme on dit dans le jargon. Vous apprendrez donc dans cet article en quoi consiste le métier de « Data Engineer », et par conséquent ce que fait une partie de notre équipe au quotidien.

La Data Engineering étroitement liée à la Data Science, fait partie de l’écosystème du Big Data. Bien que les data engineers (ingénieurs de données) ne reçoivent pas le même niveau d’attention que les data scientists, ils sont essentiels au processus de la science des données. Leur rôles et responsabilités varient en fonction du niveau de maturité des données et de l’organisation de l’entreprise.
Cependant, certaines tâches comme l’extraction, le chargement et la transformation des données, sont fondamentales et incontournables dans le métier du data engineer.
En général en ingénierie des données, on déplace des données d’un système vers un autre, ou on transforme des données dans un format vers un autre. En d’autres termes, le data engineer interroge les données d’une source (extract/extraire), effectue des traitements sur ces données (transform/transformer), et enfin place ces données d’un niveau de qualité de production, à un emplacement où les utilisateurs peuvent y accéder (load/charger). Les termes Extract, Transform et Load (ETL) correspondent aux étapes du processus présent dans les logiciels appartenant à la catégorie des ETL (comme Talend, très connu dans le milieu).
A partir d’un exemple, voyons plus en détails en quoi consiste le métier, ça vous parlera sûrement un peu plus :
Un site web de e-commerce de détail vend des gadgets « high-tech » dans une grande variété de couleurs. Le site fonctionne avec une base de données relationnelle, et chaque transaction est stockée dans la base de données.

Pour répondre à cette question, vous pouvez exécuter une requête SQL sur la base de données (SQL : Structured Query Language ; langage de requête structuré. Il s’agit c’est le langage qui est utilisé pour dialoguer et faire des traitements sur les bases de données relationnelles). Il est clair que pour une tâche simple comme celle-ci, vous n’avez pas besoin d’un data engineer mais à mesure que le site se développe, exécuter des requêtes sur la base de données de production n’est plus pratique. De plus, il peut y avoir plus d’une base de données qui enregistre les transactions, et ces bases peuvent se trouver à différents emplacements géographiques.
Par exemple, le site de e-commerce pourrait très bien avoir une base de données en Amérique du Nord, une autre en Asie, une autre en Afrique et enfin une autre en Europe.
Dans le domaine de l’ingénierie des données (la data engineering) ce genre de pratique est courante !
Pour répondre à la question précédente concernant les ventes de gadgets « high-tech » de couleurs bleus, le data engineer va créer des connexions à chacune des bases de données réparties dans les différentes régions, extraire les données, et les chargera dans un entrepôt de données. A partir de là, l’ingénieur peut maintenant effectuer une requête pour compter le nombre de gadgets bleus vendus.
Plutôt que de trouver le nombre de gadgets bleus vendus, les entreprises ont plus souvent tendance à chercher des réponses aux questions suivantes :
Pour répondre à ces questions, il ne suffit pas d’extraire les données et de les charger dans un système. Une transformation est requise entre l’extraction et le chargement. Il y a aussi la différence de fuseaux horaires dans les différentes régions. Par exemple, les Etats-Unis ont à eux seuls quatre fuseaux horaires. Pour cela, il faudra transformer les champs de date dans un format normalisé. Il faudra également trouver un moyen de distinguer les ventes dans chaque région. Cela pourrait se faire en ajoutant un champ « région » aux données. Ce champ doit-il être spatial, en coordonnées, ou sous forme de texte, ou s’agira-t-il simplement de texte qui pourrait être transformé dans un traitement d’ingénierie des données ?
Dans ce cas présent, le data engineer devra extraire les données de chaque base de données, puis transformer ces données en y ajoutant un champ supplémentaire pour la région. Pour comparer les fuseaux horaires, le data engineer doit être familiarisé avec les normes internationales de standardisation des données. Aujourd’hui, l’Organisation Internationale de Normalisation (ISO) a la norme – ISO 8601 pour faire face à cette problématique.
Donc pour répondre aux questions précédentes, l’ingénieur devra :
La suite d’étapes (extraction -> transformation -> chargement) est réalisée par la création de ce qu’on appelle un Pipeline (ou encore Job). Ce pipeline est une série de traitements successifs qui récupère en amont les données « brutes », pouvant contenir des fautes de frappe ou des données manquantes. Au fur et à mesure des traitements, les données sont nettoyées de sorte qu’à la fin du processus, ces dernières sont stockées dans un entrepôt de données et prêtes à être exploitées. Le schéma suivant illustre le pipeline requis pour accomplir les quatre tâches précédentes :
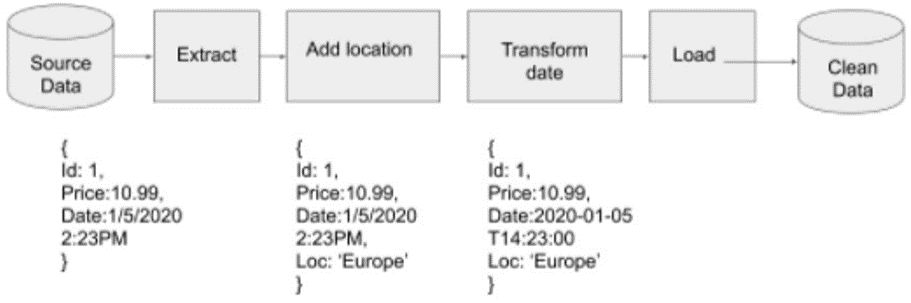
Après ce petit tour d’horizon sur ce qu’est l’ingénierie des données et ce que font les ingénieurs de données, vous devriez commencer à avoir une idée des responsabilités et des compétences que les ingénieurs de données doivent acquérir. Vrai ?
L’exemple précédent montre bien que le data engineer doit être familiarisé avec différentes technologies, et nous n’avons même pas encore mentionné les processus ou les besoins de l’entreprise.
Pour démarrer la première étape du processus d’un pipeline (l’extraction), le data engineer doit savoir comment extraire des données depuis des fichiers pouvant être en différents formats, ou depuis différents types de bases de données. L’ingénieur doit donc connaître plusieurs langages de programmation tels que SQL et Python, afin de pouvoir effectuer ces différentes tâches. Lors de la phase de transformation des données, il devra également maîtriser la modélisation et les structures de données. De plus, il doit aussi être en mesure de comprendre les besoins de l’entreprise et les informations ou connaissances qu’elle souhaite extraire des données, afin d’éviter les erreurs de conception du ou des modèles de données.
Le chargement des données dans l’entrepôt de données nécessite aussi que le data engineer connaisse les bases de conception d’un entrepôt de données, ainsi que les types de bases de données utilisés dans leur construction.
Enfin, l’ensemble de l’infrastructure sur laquelle le pipeline de données s’exécute peut également être sous la responsabilité de l’ingénieur de données. Il doit savoir comment administrer des serveurs Linux, et comment installer et configurer des logiciels tels qu’Apache Airflow ou NiFi.
Les entreprises ont de plus en plus tendance aujourd’hui à migrer vers le cloud, et incitent donc les Data engineer à se familiariser avec la mise en place de l’infrastructure sur des plateformes cloud comme Amazon, Google Cloud Platform ou Azure.
Nous sommes heureux de vous avoir partagé le métier data engineers et on espère que vous y voyez plus clair désormais !

Mettre la culture de la donnée au cœur de l’organisation est une prérogative du haut management. Il faut emmener l’ensemble de vos collaborateurs dans la transformation. Il y a parfois des freins culturels, les personnes non issues de l’ère numérique, conservent des réflexes. Du jour au lendemain, elles sont invitées à repenser leurs habitudes. Il est donc nécessaire d’adopter une conduite de changement.
Tout lancement d’un nouveau projet implique forcément des changements de processus et des changements organisationnels. Pour réussir, il vous faut communiquer pendant toute la durée du projet.
Pour créer une culture de la donnée (dite « Data Driven culture ») vous devez penser votre projet pour que les données puissent être communiquées à des non-spécialistes. Gartner précise qu’une des caractéristiques fondamentales d’une culture de la donnée est la mise à disposition de la donnée de manière simple et claire à toutes les personnes en entreprise. Par exemple, utilisez une solution logicielle de tableau de bord « retail » ou de visualisation de données pour restituer de manière claire vos données. Et par conséquent, prendre des décisions éclairées !
Vous pouvez même raconter des histoires avec vos données en leur donnant du contexte grâce aux solutions de « data storytelling » comme dans Tableau Story.
Vous pouvez rendre vos tableaux de bord simples personnalisables. Par exemple, chaque point de vente devrait être en mesure de s’approprier et d’analyser ses données « retail ». Il appréciera de pouvoir changer l’angle de vue en fonction de ses besoins. Passer d’une vision par produit, à une vision par client (B2B), ou d’une vue « directeur de magasin » à une vue « team leader », ou d’une vue produit à une vision par zone géographique, etc. La personnalisation de l’angle de vue est fondamentale pour que la donnée soit vulgarisée et comprise par l’ensemble du personnel en magasin. D’autre part, vu le nombre d’informations auxquelles il est exposé, il est important de rester simple pour une communication efficace.
Vous devez intéresser le personnel de vos magasins par les données qui sont à sa disposition. Vos collaborateurs doivent voir des solutions à leurs problématiques métiers dans le projet ; c’est une étape essentielle pour un projet data réussi. Par exemple, la rémunération variable du personnel est souvent fonction des résultats des ventes du magasin. Lui donner des solutions concrètes pour mieux vendre est donc dans son intérêt.
Fournir des tableaux de bord retail personnalisés et simples, est un enjeu de votre projet. Imaginez un mini site internet fournissant au directeur du magasin le tutoriel sur la nouvelle disposition des articles en magasin, l’emploi du temps de la semaine, les performances de vente par produit…Une mini-plateforme personnalisée lui fournissant des informations pour lui et son équipe : le rêve !
Si vous souhaitez la réussite de votre organisation (on n’en doute pas une seule seconde !), vous devez penser « adoption par les collaborateurs » de votre projet.
Le défaut de nombreux projets data est qu’ils naissent sans être pensés pour des cas d’usage métier précis. La donnée est privilégiée au détriment de l’apport métier. Nous pensons que c’est une vision purement technique de voir les choses ! Avoir les données à disposition n’est pas le but du projet data. La finalité est de pouvoir fournir des informations actionnables à des professionnels et répondre à leurs problématiques.
La Data permet de réhabiliter l’efficacité des stratégies marketing en offrant aux retailers l’approche « ROIste » qu’ils réclament. Le Data Storytelling permet, lui, de légitimer et valoriser les choix en systèmes d’information qui récupèrent cette Data, en la racontant aux magasins. Ces derniers peuvent désormais prendre les meilleures décisions.
La Data est votre nouvelle monnaie. Mieux que de l’échanger, il faut la faire fructifier et la rendre exploitable. La question n’est plus « Pourquoi ?», mais « Quand ?». Faites-nous confiance, nous nous occupons du « Comment ?».
Article 1 : https://www.datanalysis.re/blog/business-intelligence/retail-meilleures-data-meilleurs-resultats-s3e1/
Article 2 : https://www.datanalysis.re/blog/business-intelligence/retail-maitriser-vos-donnees-metiers-s3e2/
Artcicle 3 : https://www.datanalysis.re/blog/business-intelligence/retail-data-science-insights-s3e3/

En plongeant dans ces informations à un niveau fin, l’utilisateur peut découvrir et comprendre des tendances et des comportements complexes. Il s’agit de faire remonter à la surface des informations pouvant aider les entreprises à prendre des décisions plus intelligentes.
Cette « fouille de données » peut se faire grâce à l’apprentissage automatique (Machine Learning). Ce dernier fait référence au développement, à l’analyse et à l’implémentation de méthodes et algorithmes qui permettent à une machine (au sens large) d’évoluer grâce à un processus d’apprentissage, et ainsi de remplir des tâches qu’il est difficile ou impossible de remplir par des moyens algorithmiques plus classiques.
Un data product est un outil qui repose sur des données et les traite pour générer des résultats à l’aide d’un algorithme. L’exemple classique d’un data product est un moteur de recommandation.

Il a été rapporté que plus de 35% de toutes les ventes d’Amazon sont générées par leur moteur de recommandation. Le principe est assez basique : en se basant sur l’historique des achats d’un utilisateur, les articles qu’il a déjà dans son panier, les articles qu’il a notés ou aimés dans le passé et ce que les autres clients ont vu ou acheté récemment, des recommandations sur d’autres produits sont automatiquement générées.
Un autre exemple de cas d’usage de la data science est l’optimisation de l’inventaire, les cycles de vie des produits qui s’accélèrent de plus en plus et les opérations qui deviennent de plus en plus complexes obligent les détaillants à utiliser la Data Science pour comprendre les chaînes d’approvisionnement et proposer une distribution optimale des produits.
Optimiser ses stocks est une opération qui touche de nombreux aspects de la chaîne d’approvisionnement et nécessite souvent une coordination étroite entre les fabricants et les distributeurs. Les détaillants cherchent de plus en plus à améliorer la disponibilité des produits tout en augmentant la rentabilité des magasins afin d’acquérir un avantage concurrentiel et de générer de meilleures performances commerciales.
Ceci est possible grâce à des algorithmes d’expédition qui déterminent quels sont les produits à stocker en prenant en compte des données externes telles que les conditions macroéconomiques, les données climatiques et les données sociales. Serveurs, machines d’usine, appareils appartenant au client et infrastructures de réseau énergétique sont tous des exemples de sources de données précieuses.

Ces utilisations innovantes de la Data Science améliorent réellement l’expérience client et ont le potentiel de dynamiser les ventes des détaillants. Les avantages sont multiples : une meilleure gestion des risques, une amélioration des performances et la possibilité de découvrir des informations qui auraient pu être cachées.
")
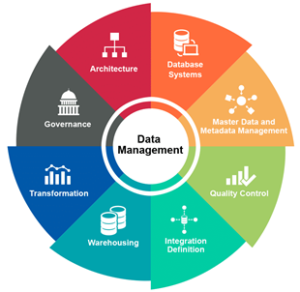
Le MDM consiste à centraliser la gestion de données dites essentielles intéressant les grandes applications de l’entreprise. Il implique une réflexion plus globale sur l’urbanisation du SI. Tant du point de vue des données que des processus.
Pour mieux cerner la notion de « gestion des données de référence », faisons un tour d’horizon de ce domaine, des fonctionnalités proposées par les outils du marché, et les principaux acteurs.
Le référentiel de données n’est pas une notion nouvelle. Mais le MDM est lui un concept émergent qui prend toute sa dimension aujourd’hui. En effet, la complexité croissante des systèmes d’information souvent éclatés suite à des réorganisations d’entreprises, la volumétrie croissante des informations à gérer, la multiplication des contraintes réglementaires obligent le gestionnaire à mieux maîtriser les informations clés de l’activité de l’entreprise : clients, produits, fournisseurs, etc.
Si la notion de dictionnaire ou « référentiel de données » n’est pas nouvelle, le concept-même de MDM est apparu en 2003 et prend vraiment son essor actuellement. Historiquement, celui-ci s’est développé dans des contextes très verticalisés, et sous deux angles :
– La gestion des catalogues produits (ou PIM pour Product Information Management) notamment dans les domaines de la grande distribution (retail) et du manufacturing,
– L’intégration des données clients (ou CDI pour Customer Data Integration) particulièrement pour l’administration de grosses bases de données transactionnelles (gestion des doublons, vérification et homogénéisation des adresses, etc.).
Ce concept désormais d’autres problématiques et concerne la gestion des tiers et personnes, des produits et des offres, de l’organisation et des structures͕ des nomenclatures et des codifications, de la configuration et des paramètres.

Face à la mondialisation et à l’ouverture des marchés͕ les entreprises et organismes publics connaissent de multiples restructurations et opérations de fusion et doivent s’adapter à des contextes d’internationalisation pour se maintenir dans la course et s’ouvrir de nouvelles opportunités de business. Ces structures doivent faire face à de multiples contraintes qui régissent leur environnement :
– La complexité croissante des contraintes réglementaires (Bâle II, IFRS, MIF, etc.) nécessite de collecter plus de données, de justifier davantage les opérations, d’avoir plus de transparence au niveau de la présentation des résultats,
– Une compétitivité plus forte : face à la mondialisation et à l’ouverture des marchés, il faut être en mesure d’anticiper les tendances du marché, mettre en place de nouvelles offres pour répondre aux clients exigeants, répondre à la pression des actionnaires, et enfin pouvoir se mesurer régulièrement à la concurrence,
– Les impératifs de rentabilité sont incontournables face à l’accroissement des risques opérationnels,
–Une organisation centrée sur le client : il s’agit de lui proposer le bon produit, sur le bon canal au bon moment.
En interne aussi, la gestion de l’information est soumise à des contraintes nombreuses et complexes dues à :
– La multiplication des systèmes et applications,
– La multiplication des données (structurées ou non) avec la dispersion, la redondance et les incohérences sur les données les plus essentielles, les désaccords internes sur la valeur à attribuer à telle ou telle donnée, les définitions incorrectes sur certaines données, la difficulté d’accès et de manipulation des données͕ l’absence de gestion unifiée et maîtrisée des données clés de l’entreprise,
– L’apparition de nouveaux impératifs métier qui nécessitent d’avoir l’information quasi en temps réel , et de se doter des bons indicateurs pour réduire les risques opérationnels.
Parmi les fonctions du Master Data Management, on distingue :
– Les fonctions de base : la gestion du référentiel centralisé, la gestion de catalogues multiples (clients, produits, etc.), la gestion du cycle de vie des données, la gestion des versions Développement, test, production), la gestion des types et liens entre données,
– L’intégration : la synchronisation; le profiling de données et la gestion de la qualité de données, la réplication͕ la transformation͕ l’intégration des données et applications ;au sens chargement ETL des données),
– La modélisation : les outils de modélisation, la découverte et le mapping des données, la gestion des hiérarchies complexes et sémantiques,
– La gouvernance la gestion de la sécurité͕ l’interface utilisateur métier͕ les fonctions de recherche et d’accès͕ le workflow,
– Les fonctions avancées : l’évolutivité, pour étendre le référentiel à d’autres catégories de données via des modèles de données standardisés et extensibles ; la présence d’un moteur de règles, pour piloter et conditionner les processus de mise à jour dans les référentiels ; les fonctions natives de workflow enrichies d’étapes de validation humaines lors du design des flux, la réconciliation des données clients produits entre les différentes applications des fonctions exposées sous forme de Web services pour faciliter le dialogue synchrone avec le référentiel, l’intégration native avec les outils ETL (Outils d’intégration de données) et les outils de gestion de qualité des données.
L’entreprise avait besoin de gérer ses données référentielles afin d’optimiser ses ventes et profits
Création d’une stratégie Data orientée Client en 3 grands axes :
Un projet MDM vise à urbaniser l’administration des données en différenciant bien ce qui est du ressort des applications opérationnelles et des données locales et au contraire ce qui revient au MDM et à la gestion des données de référence d’entreprise͘. Modélisation, intégration et gouvernance sont les grands axes de réflexion des projets MDM͕ lesquels doivent se doter d’une méthodologie rigoureuse assortie des meilleures pratiques.
On peut parler de données de qualité lorsque les 4 caractéristiques suivantes sont réunies :
Malgré la tendance qui met de plus en plus en avant l’importance de disposer de données fiables pour prendre les bonnes décisions stratégiques et commerciales, de nombreuses entreprises hésitent encore à véritablement investir dans ce sens et pensent avant tout à réduire leurs coûts.
")
Si oui, dans ce cas, vous passez à côté de données précieuses pour augmenter vos ventes, attirer plus de clients et mettre de côté les dépenses inutiles.
Il ne suffit pas de consulter ses statistiques de CA et fréquentation pour assurer un véritable pilotage par la data.
La qualité des données est indispensable et permet d’optimiser plusieurs axes :
Des données bien paramétrées et prêtes à être analysées selon vos objectifs vous permettront par exemple d’identifier en un clin d’œil vos tendances de vente par produits, de mieux comprendre ce qui fonctionne auprès de vos clients, mais aussi de réduire les coûts de campagnes selon leur ROI, d’anticiper vos lancements et de limiter les risques…
Comment faire pour avoir de meilleures données ??
Les dirigeants les mieux informés reconnaissent l’importance d’établir et d’institutionnaliser les pratiques exemplaires pour améliorer l’utilisation des données. L’objectif premier est d’élever le niveau de qualité de l’information. Cependant, des problèmes peuvent apparaître si les entreprises entament des efforts sporadiques pour les nettoyer et les corriger. L’absence de processus exhaustifs réservés à la gestion de la « qualité de données » entraîne la multiplication des interventions, et de fait l’augmentation des coûts. Pire encore, cela entrave la distribution d’informations cohérentes auprès des utilisateurs métiers.
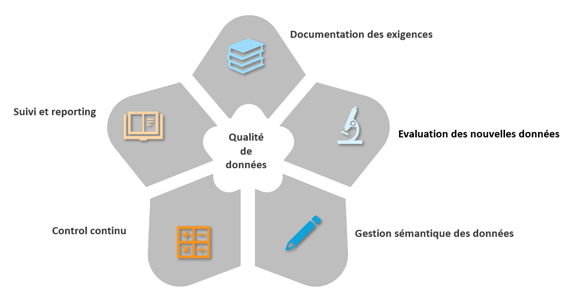
Il convient alors d’adopter une approche pragmatique afin d’aligner les pratiques disparates en termes de maintien de la qualité des données. Cette démarche permet de mettre en place un programme à l’échelle d’une société afin de relever ces deux défis. Au-delà du fait de se rapprocher de partenaires commerciaux, de développer des cas d’usage et d’élaborer une analyse du retour sur investissement, il faut lister les procédures essentielles à l’amélioration de cette « qualité de données ».
Dans la majorité des cas, accroître la qualité des données consiste à améliorer la pertinence des informations commerciales. Pour ce faire, les organisations doivent commencer par collecter les besoins. Cela implique une collaboration avec les utilisateurs métiers afin de comprendre leurs objectifs commerciaux. Une fois cette étape finalisée, ces informations combinées à des expériences partagées sur l’impact commercial des problèmes liés à la qualité de données peuvent être transformées en règles clés. Celles-ci mesurent la fraîcheur, l’exhaustivité et la pertinence des données.
Un processus reproductible d’évaluation des données permet de compléter l’ensemble des règles de mesure, en scrutant les systèmes sources à la recherche d’anomalies potentielles dans les nouvelles données. Les outils de profilage permettent de balayer les valeurs, les colonnes et les relations dans et entre les sources de données. Mener cette opération fréquemment facilite l’identification des valeurs aberrantes, les erreurs et renforce leur intégrité. Ces outils permettent également de renseigner les administrateurs quant aux types de données, la structure des bases de données, et sur les interactions entre les entités. Les résultats peuvent être partagés avec les métiers pour aider à élaborer les règles de validation de la qualité des données en aval.
Au fur et à mesure que le nombre et la variété des sources de données augmentent, il est nécessaire de limiter le risque que les utilisateurs finaux des différentes divisions d’une organisation interprètent mal ce surplus d’informations. L’on peut centraliser la gestion des métadonnées (dictionnaire de données) commercialement pertinentes et engager les utilisateurs et le Chief Data Officer (Directeur des données) à collaborer. Il s’agit d’établir des standards afin de réduire le nombre de cas où de mauvaises interprétations entraînent des problèmes d’exploitation des données. Les métadonnées et les librairies associées peuvent être accessibles depuis le Catalogue de données dans le but de comprendre les informations disponibles.
Ensuite, il est recommandé de développer des services automatisés pour valider les données enregistrées, services qui adopteront les règles de qualités préalablement définies. Un déploiement stratégique facilite le partage des règles et des mécanismes de validation à travers l’ensemble des applications et dans tous les flux informatiques, afin d’assurer une inspection continue et la mesure de la qualité des données. Les résultats peuvent être intégrés à divers systèmes de rapports tels que des notifications et des alertes directes envoyées aux responsables de la gestion des données pour traiter les anomalies les plus graves et les failles de données hautement prioritaires, ainsi que des tableaux de bord figurant des agrégats pour les collaborateurs non-initiés.
En ce sens, il est pertinent de développer une plateforme pour enregistrer, suivre et gérer les incidents liés à la « qualité de données ». Il ne suffit pas de comparer les règles mises en place. En soi, cet effort n’entraîne pas d’amélioration à moins qu’il y ait des processus standards pour évaluer et éliminer la source des erreurs. Un système de gestion des événements peut automatiser les tâches de reporting, mettre en avant les urgences, alerter les responsables, assigner les tâches et suivre les efforts d’assainissement.

Bien menées, ces méthodes de « Data Governance » constituent l’épine dorsale d’un cadre proactif de gestion de la qualité des données, assorti de contrôles, de règles et de processus qui peuvent permettre à une organisation d’identifier et de corriger les erreurs avant qu’elles n’aient des conséquences commerciales négatives. En fin de compte, ces procédures permettront une meilleure exploitation des ressources au bénéfice des entreprises qui les déploient.
Vous assurer des données de qualité ne devrait jamais être considéré comme une dépense, mais bien comme un investissement… rentable !