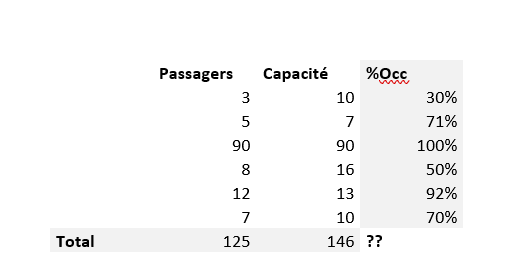
La Prime Régionale pour l’Emploi de FEDER, un soutien essentiel pour notre croissance
Le développement d’une entreprise passe par différentes étapes et nécessite souvent le soutien de partenaires et d’organismes pour assurer sa croissance. Récemment, notre société a bénéficié d’une Prime Régionale pour l’Emploi de la part du Fonds Européen de Développement Régional (FEDER) pour la création de trois postes supplémentaires. Cette aide a été déterminante dans le développement de notre équipe et nous sommes heureux de partager notre expérience avec vous.
L’aide financière accordée par le FEDER a été un véritable catalyseur pour notre entreprise. En effet, grâce à cette prime, nous avons pu embaucher trois nouveaux collaborateurs aux compétences diverses et complémentaires. Ces nouvelles recrues ont permis d’étoffer notre équipe et de renforcer notre expertise dans des domaines clés pour notre activité.

Cet appui financier a également eu un impact positif sur notre environnement local. En créant de nouveaux emplois, nous contribuons au développement économique de notre région et à la réduction du chômage. De plus, la Prime Régionale pour l’Emploi nous a incités à recruter des personnes résidant à proximité de notre entreprise, favorisant ainsi la cohésion sociale et le dynamisme de notre territoire.
En outre, cette prime a également contribué à améliorer la qualité de nos services et produits. Les compétences apportées par nos nouvelles recrues nous ont permis d’innover et d’optimiser nos processus internes. Ainsi, notre entreprise est devenue plus compétitive sur le marché, tout en offrant des opportunités de carrière à des personnes talentueuses.
Enfin, cette expérience nous a démontré l’importance de l’accompagnement et du soutien des organismes tels que le FEDER. Cela nous a également encouragés à nous rapprocher d’autres partenaires et à rechercher d’autres opportunités de financement et de développement pour notre société.
En conclusion, la Prime Régionale pour l’Emploi de FEDER a été un tremplin essentiel pour notre entreprise et notre équipe. Grâce à cet appui, nous avons pu créer de nouveaux emplois, renforcer notre expertise, et contribuer au développement économique local. Nous remercions chaleureusement le FEDER pour son soutien et sommes impatients de poursuivre notre croissance en partenariat avec d’autres acteurs de notre écosystème régional.